
- Transport Layer
Transport Layer
Transport-Layer Services
相比运行在hosts(IP地址)之间的网络层协议,传输层协议运行在不同hosts的processes之间,实现logical communication,且其部署在end systems中而非routers中。网络层协议有UDP与TCP,两者都提供多路复用/解复用与错误检测的服务,但TCP还提供可靠数据传输、流控制、拥塞控制的服务。
Multiplexing & Demultiplexing
在多主机、多应用、多进程、多socket上,不同应用间的通信是通过segment在socket中传输实现的,多路复用/解复用就用于定位一个segment的目的socket与源socket是什么,解复用是发送至socket,多路复用是从socket接收并发至网络层,这通过两者实现:1)唯一标识符socket,2)segment中指定源与目的socket port number。UDP socket只关注目的地,而TCP socket由于面向连接,会建立源-目的地的一对一连接。
UDP
UDP header中有源端口号、目的端口号(用于多路复用/解复用),length与checksum(提供data integrity服务,将16bit data相加后取反,进位时最低位+1,接收时data+checksum全为1则说明无误)。使用UDP的应用有:DNS(实时性、无需连接、减小内存占用、UDP header字节更少更轻量),SNMP,NFS。
RDT
- rdt1.0:假设信道完全可靠,接收方无需任何feedback。
- rdt2.x:假设信道存在bit error,即packet可能受损但不丢包。
- rdt2.0:接收方采用ACK, NAK, ARQ,接收方确认收到传送ACK,出错传送NAK,发送方收到NAK则重传。
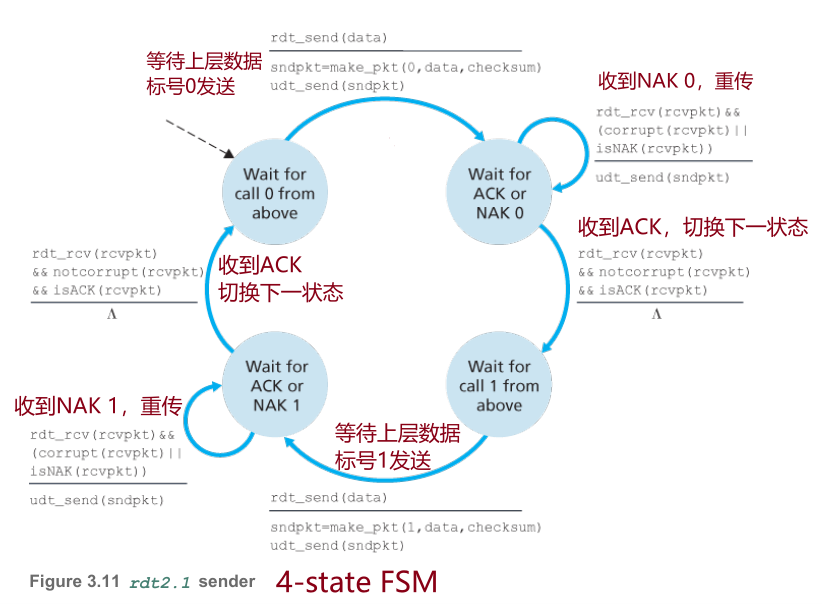
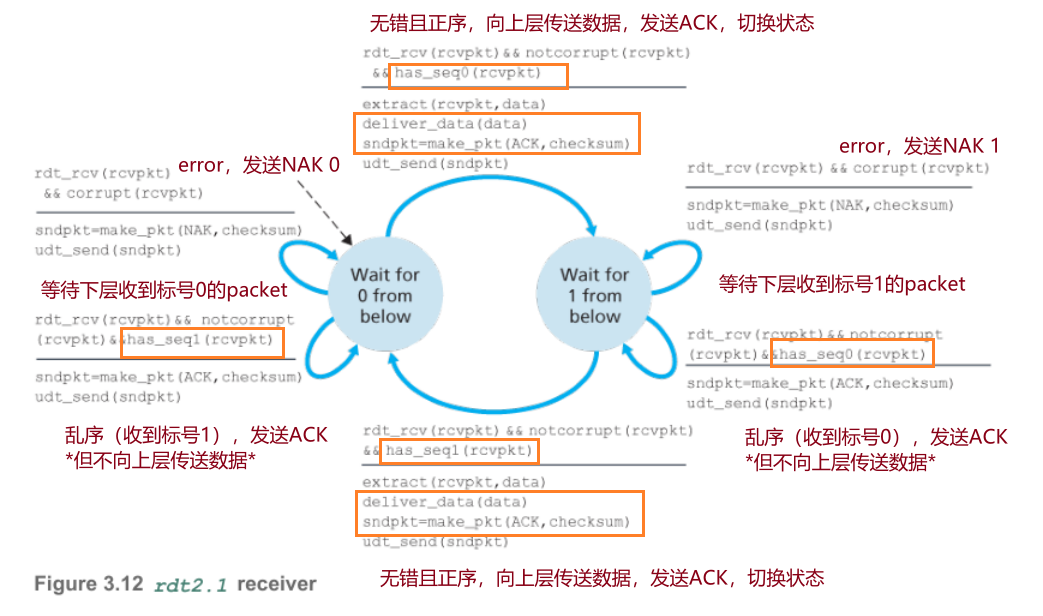
- rdt2.1:假设ACK/NAK packet也可能受损,发送方只要收到受损的feedback packet就重传,为排除冗余packet,为数据packet添加单bit序号字段1/0,接收方使用ACK, NAK 1/0。
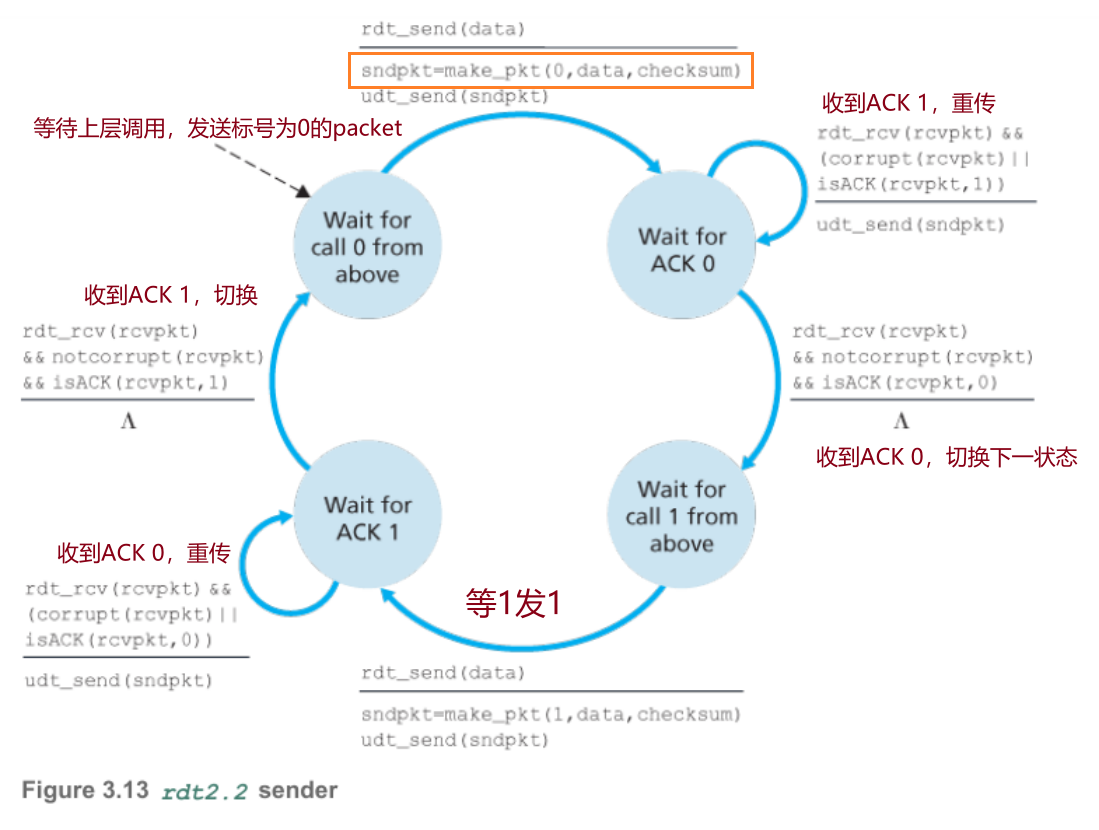
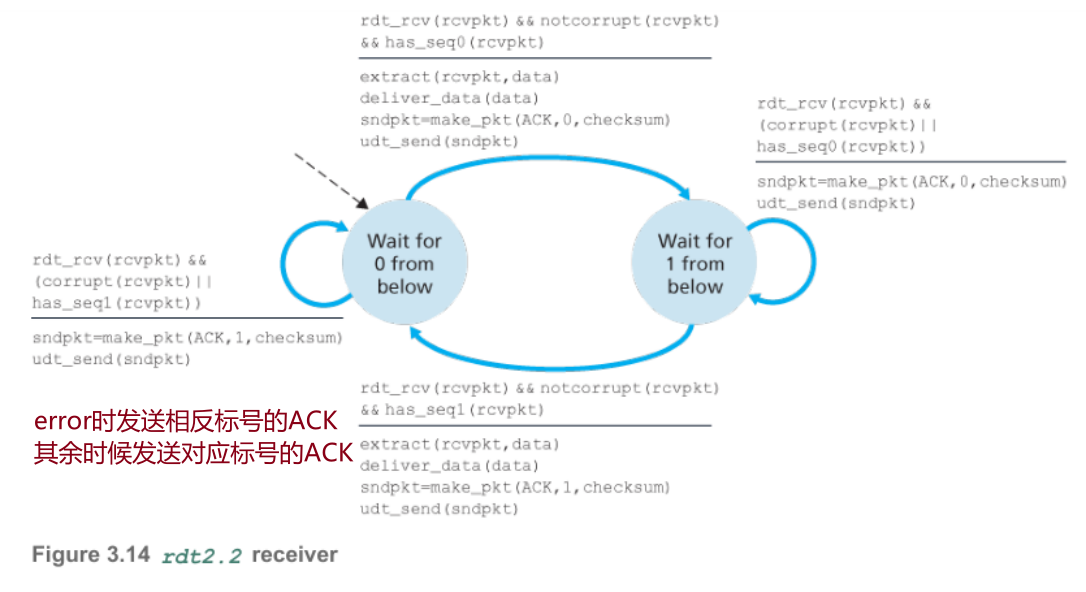
- rdt2.2:接收方移除NAK,采用ACK 1/0。
- rdt3.0:假设信道存在bit error且lossy,即packet可能受损或可能丢包,发送方发送每个packet时启动定时器,超时则重传,接收方使用ACK 1/0。
- pipelined:rdt协议的缺陷是由于其核心为停等协议,每次传输都至少要等待一个RTT,因此采用流水线设计,不需要等待前序packet被确认收到。
- Go Back N:序号范围扩大,双方都需要维持缓冲区。发送方维护一个全局计时器和一个窗口(base,nextseqnum),base为最小未确认packet的序号,每次更新base时重启计时器,超时重传当前窗口所有未确认的分组。接收方采用累计确认ACK k,不符合当前需求序号k的packet一律丢弃,即接收方保证正确、正序确认packet。
- Selective Repeat:双方都维持缓冲区和窗口,且由于feedback的延迟或丢包,窗口不同步。发送方为每个分组维持一个定时器,超时重传。接收方只要确认收到当前窗口和上一窗口范围内的分组,就发送ACK k(即使冗余),防止由于ACK丢失,发送方一直重传。
TCP
TCP的特征为面向连接(体现在3次握手)、全双工、点对点(多重广播)、双向传输。
TCP的连接管理:
- 3次握手:client开辟连接,发送SYN segment(SYN=1),server发送SYNACK segment(单独ACK不包含任何数据,不是捎带确认,该确认segment中会给予该SYN segment一个cookie,此时不开辟连接,防止SYN flood attack),client发送ACK segment,可能包含请求数据,收到后server开辟连接。
- 关闭连接:client发送FIN segment(FIN=1)请求关闭,server发送ACK确认后一段时间再发送FIN segment,client确认后,两端真正关闭连接。
TCP提供RDT、流控制、拥塞控制服务。
- RDT:发送方维持一个定时器,超时重传,并累计确认,收到冗余ACK就快速重传,无需等到超时。
- 流控制:在header中维持一个receive window(用最后读取、最后接收、最后发送、最后确认与buffer size来表示)。
- 拥塞控制:
- 通过cwnd控制速度;
- 丢包(超时/冗余ACK x3)视为拥堵,收到一个ACK则增大cwnd,pushy strategy;
- 拥塞控制算法:初始cwnd=MSS,慢启动(cwnd+=MSS,指数增长)、拥塞避免(cwnd+=MSS*MSS/cwnd,线性增长)、快速恢复(cwnd+=MSS,指数增长),只要丢包(timeout/duplicate ACK)ssthresh=cwnd/2(乘性减半)且重传,超时则重启慢启动,冗余ACK则cwnd=ssthresh+3MSS,进入快速恢复,直到首次收到新的ACK,视为拥塞结束,进入拥塞避免。
1. Transport-Layer Services
Conclusion:相比运行在hosts(IP地址)之间的网络层协议,传输层协议运行在不同hosts的processes之间,实现logical communication,且其部署在end systems中而非routers中。网络层协议有UDP与TCP,两者都提供多路复用/解复用与错误检测的服务,但TCP还提供可靠数据传输、流控制、拥塞控制的服务。
服务:传输层协议提供了运行在不同hosts上运行的processes实现逻辑通信logical communication(指他们在逻辑上直接连接,但实际上可能经过了无数routers)。相对的,一个网络层协议在hosts之间实现逻辑通信。传输层协议能提供的服务被底层的网络层协议所限制。
部署:传输层协议在end systems中实现而非routers中,路由器只负责转发datagram。
行为:传输层协议将应用层message封装为传输层message,传输给网络层,网络层再封装成数据报datagram。也就是说每一层就都会将数据封装为能在该层传输、向下层传输的packet。
1.1 Transport layer protocols
between processes running on hosts
UDP(User Datagram Protocol)-datagram/segment
TCP(Transmission Control Protocol)-segment
两者都有/UDP仅有的services:
- transport-layer multiplexing and demultiplexing 传输层的多路复用与解复用,将host-host delivery扩展到process-process delivery
- integrity/error checking
TCP独有:
- reliable data transfer
- congestion control
1.2 Network Layer protocols
between hosts(IP addresses)
IP(Internet Protocol)-datagram
services:
best-effort delivery service
no guarantees, unreliable service
2. Multiplexing & Demultiplexing
Conclusion:在多主机、多应用、多进程、多socket上,不同应用间的通信是通过segment在socket中传输实现的,多路复用/解复用就用于定位一个segment的目的socket与源socket是什么,解复用是发送至socket,多路复用是从socket接收并发至网络层,这通过两者实现:1)唯一标识符socket,2)segment中指定源与目的socket port number。UDP socket只关注目的地,而TCP socket由于面向连接,会建立源-目的地的一对一连接。
已知:多主机,多应用,一个应用对应多进程,一个进程对应多socket(多线程),segment要通过socket传输。
需求:问题在于如何找到正确的socket,多路复用/解复用服务能解决这个问题。所有计算机网络都需要多路复用/解复用服务。
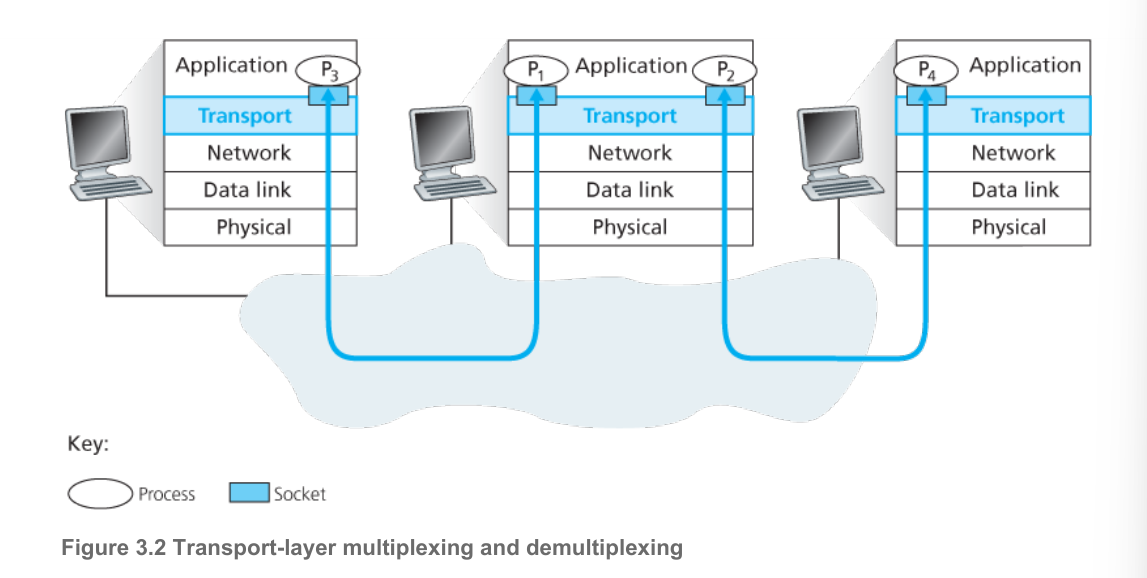
2.1 definition
demultiplexing,解复用,就是将transport-layer segment中的data传送到正确的socket中
multiplexing,多路复用,将从不同socket接收到的data chunks封装成segments,添加头信息(用于解复用),发送至network layer
要实现这项技术这需要:
unique identifiers for sockets 唯一标识符socket
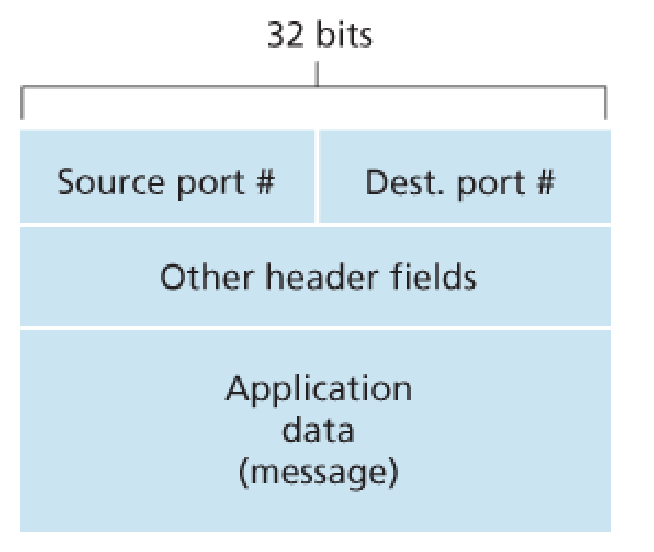
segment中含有字段指定destination socket,而这包括source port number & destination port number(每个端口号都是16-bit number,传输层一般指定1024-65535 ,0-1023是著名端口号,一般为一些广泛使用的application保留,如HTTP-80)
![image-20230214175055942]()
一般来说,应用的client side会让传输层自动生成socket端口号,而server side则指定一个特定端口号
2.2 Multiplexing & Demultiplexing in UDP
$return\ address = source\ port\ number + source\ IP\ address$
$UDP\ socket= (destination\ IP\ address,\ destination\ port\ number)$
UDP只关注目的地,一个UDP socket能接收source不同、发送destination不同的信息。
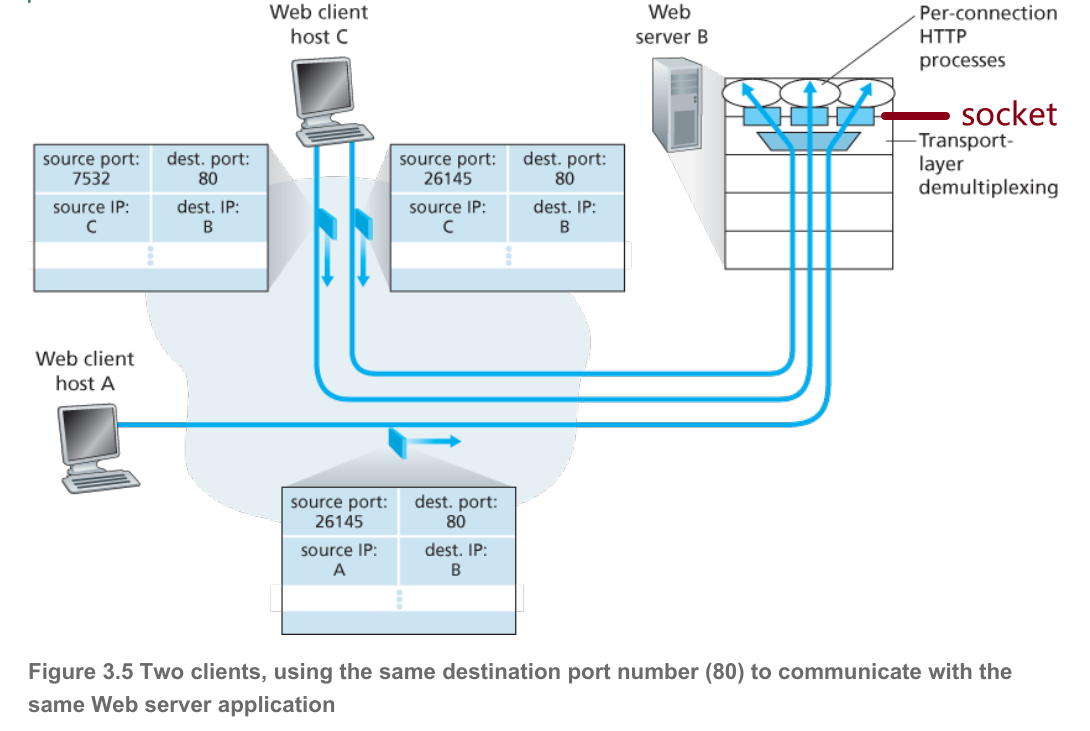
2.3 Multiplexing & Demultiplexing in TCP
$TCP\ socket=(source\ IP\ address,\ source\ port\ number,\ destination\ IP\ address,
destination\ port\ number)$
TCP关注source & destination,完全双向一对一连接。
原理:
- TCP server具有一个welcoming socket,用于等待连接请求
- TCP client创建一个socket,通过其发送连接请求segment,会在其中指定其该四元组
- TCP server收到连接请求后,根据该请求segment中的四元组创建一个新的socket
2.4 Security
攻击者可以监听/攻击一些知名应用的默认端口,造成其缓冲区溢出,可能可以在该主机上执行任何代码。因此有必要查询本机中监听端口的进程,可以用nmap。
3. UDP(User Datagram Protocol)
Conclusion:UDP header中有源端口号、目的端口号(用于多路复用/解复用),length与checksum(提供data integrity服务,将16bit data相加后取反,进位时最低位+1,接收时data+checksum全为1则说明无误)。使用UDP的应用有:DNS(实时性、无需连接、减小内存占用、UDP header字节更少更轻量),SNMP,NFS。
UDP从应用程序进程中获取消息,为多路复用/解复用服务附加源端口号和目的端口号字段,添加另外两个小字段,并将结果段传递给网络层。
why connectionless: no handshaking before communication
3.1 UDP segment structure
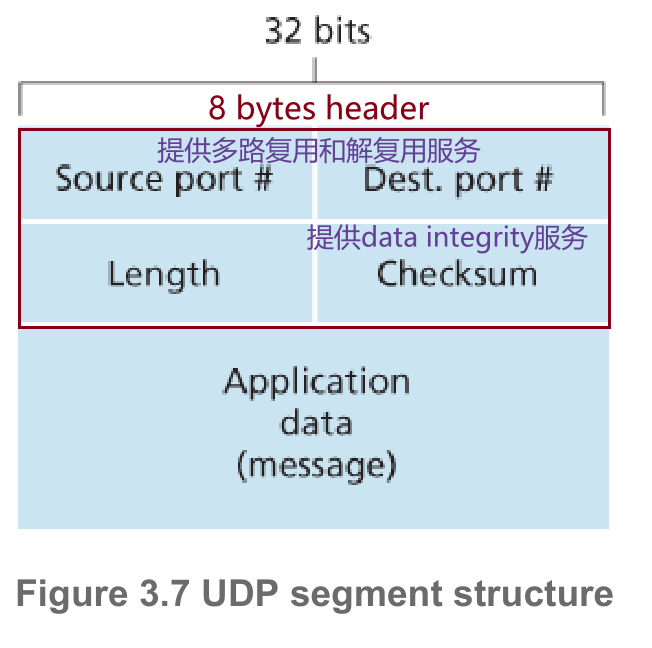
UDP header有8 bytes,指定了源和目的的端口号用于multiplexing & demultiplexing,而源IP和目的IP是由network layer封装的,在IP datagram header,作为伪UDP segment header。
3.1.1 checksum
UDP提供error detection功能,考虑到既不能保证链路的可靠性(link-layer protocol不提供reliability)也不能保证内存中的错误检测,如果端端数据传输服务要提供错误检测,UDP必须在传输层提供端到端错误检测,但是UDP只检查错误,废除segment或warning,不会correct。类似based on UDP的应用可以在应用层提供可靠数据传输,主要是衡量在更低或更高级别实现该功能的成本与必要性。UDP header中用checksum检测是否出错:
- 发送方将segment中所有的16-bit字相加,循环进位(进位时最低位+1),再求反码(对无符号二进制数字来说,先反后加和先加后反是一样的),作为header中checksum字段的值,发送segment
- 接收时计算data中所有的16-bit字与header中checksum之和,若全为1则正确,若有一个0则说明该packet出错
3.2 Applications running on UDP
- DNS
- Finer application-level control over what data is sent, and when 应用程序级控制什么时间发送什么数据(TCP有拥堵控制,会造成延迟,有些应用能够容忍data loss)
- No connection establishment 无需连接,三次握手很耗时;这就是为什么DNS用UDP。HTTP用TCP(需要可靠数据传输),针对使用后者造成的延迟,chrome使用QUIC protocol(Quick UDP Internet Connection,在UDP作为传输层协议的基础上,在应用层协议上实现了可靠数据传输)
- No connection state 记录连接状态需要缓冲区与拥堵控制参数,会占用内存
- Small packet header overhead,TCP segment header-20 bytes,UDP segment header-8 bytes
- SNMP(network management)
- NFS(remote file server)
4. Reliable Data Transfer
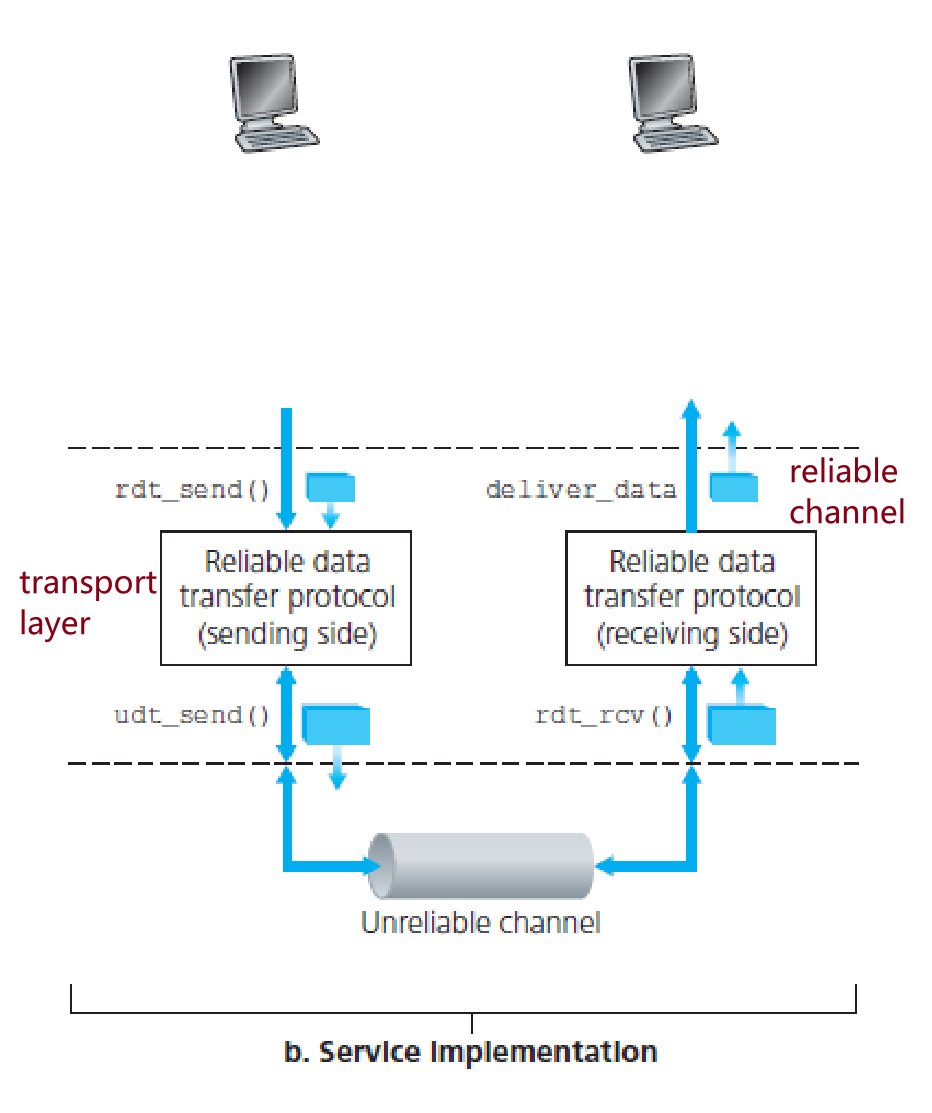
本章只讨论unidirectional data transfer(only sender->receiver)的RDT protocols。
bidirectional(full-duplex)
| 参考:[可靠数据传输原理 | YieldNull](https://yieldnull.com/blog/943b65e3a64843303b8f15e1acbf79a77ace947f/#21-rdt-21-acknak) |

Conclusion:
- rdt1.0:假设信道完全可靠,接收方无需任何feedback。
- rdt2.x:假设信道存在bit error,即packet可能受损但不丢包。
- rdt2.0:接收方采用ACK, NAK, ARQ,接收方确认收到传送ACK,出错传送NAK,发送方收到NAK则重传。
- rdt2.1:假设ACK/NAK packet也可能受损,发送方只要收到受损的feedback packet就重传,为排除冗余packet,为数据packet添加单bit序号字段1/0,接收方使用ACK, NAK 1/0。
- rdt2.2:接收方移除NAK,采用ACK 1/0。
- rdt3.0:假设信道存在bit error且lossy,即packet可能受损或可能丢包,发送方发送每个packet时启动定时器,超时则重传,接收方使用ACK 1/0。
- pipelined:rdt协议的缺陷是由于其核心为停等协议,每次传输都至少要等待一个RTT,因此采用流水线设计,不需要等待前序packet被确认收到。
- Go Back N:序号范围扩大,双方都需要维持缓冲区。发送方维护一个全局计时器和一个窗口(base,nextseqnum),base为最小未确认packet的序号,每次更新base时重启计时器,超时重传当前窗口所有未确认的分组。接收方采用累计确认ACK k,不符合当前需求序号k的packet一律丢弃,即接收方保证正确、正序确认packet。
- Selective Repeat:双方都维持缓冲区和窗口,且由于feedback的延迟或丢包,窗口不同步。发送方为每个分组维持一个定时器,超时重传。接收方只要确认收到当前窗口和上一窗口范围内的分组,就发送ACK k(即使冗余),防止由于ACK丢失,发送方一直重传。
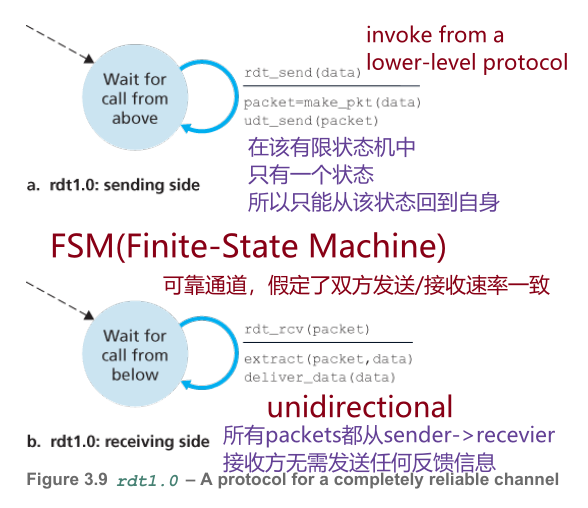
4.1 rdt1.0
完全可靠信道,假定双方发送/接收速率一致,理想状态,也最简单,一发一收就行,接收方无需任何反馈信息。
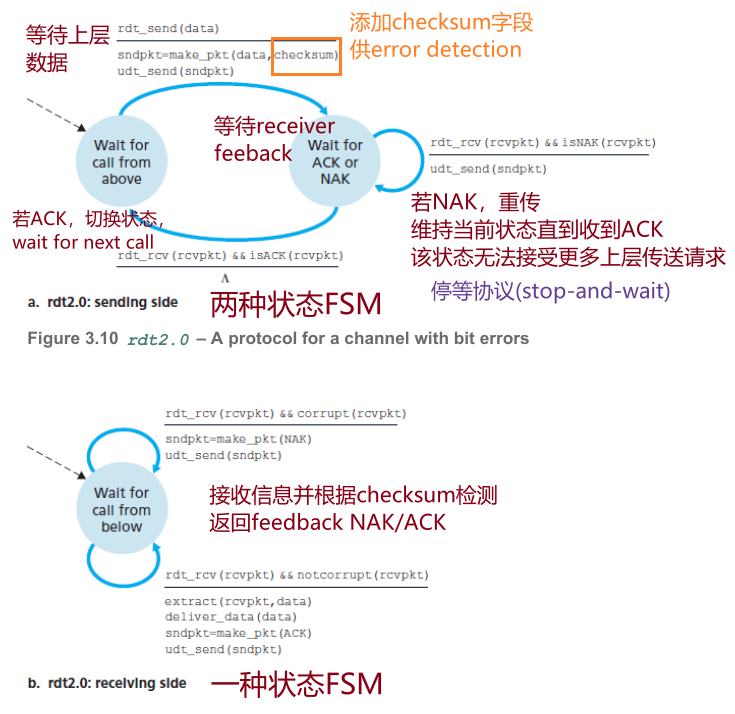
4.2 rdt2.0
比特差错信道,收到的packet可能受损。
需要以下功能:
ACK(postive acknowledg)
NAK(negative acknowledge)
ARQ(Automatic Repeat reQuest),自动重传请求,存在比特差错则请求重传
实现ARQ还需要三种协议功能:检测、反馈、重传
- error detection, 发送方在packet中添加额外的checksum bit字段用于检测
- receiver feedback,接收方反馈是否正确接收
- retransmission,发送方重传
但ACK/NAK packet的命也是命
但ACK/NAK packet也可能受损,解决方法是:
- 收到受损的feedback packet就直接重传,这样会导致冗余分组(duplicate packet),即接收方不确定该packet是新packet还是重传
- 针对这个问题,发送方为每个packet添加序号字段,接收方检测其序号即可确定是否重传(对于停等协议,由于发送方必须确保当前特定packet送达才能继续传送下一个,时序性是一定的,只要确定序号字段是否改变即可,可以用1/0)
4.2.2 rdt2.1
针对ACK/NAK packet可能受损的问题进行改进,发送方为每个packet添加单bit序号1/0,只要收到受损的feedback packet就重传,接收方通过检测序号是否匹配状态来判断是否冗余分组。
4.2.2 rtd2.2
移除了NAK,只使用ACK 1/0。
发送方:收到的ACK序号与状态不匹配则重传,反之switch
接收方:若packet受损则发送与状态相反的ACK,反之发送与packet序号一致的ACK
4.3 rdt3.0
比特差错、丢包信道,现在涉及到受损、丢包、超时和乱序的情况,相比rdt2.2,发送方每次发送packet都会启动定时器。
- 检测丢包(设置定时器,不论能否确定丢包都重发)
- 丢包后如何弥补(ARQ,重传机制;rdt2.2,处理冗余packet)
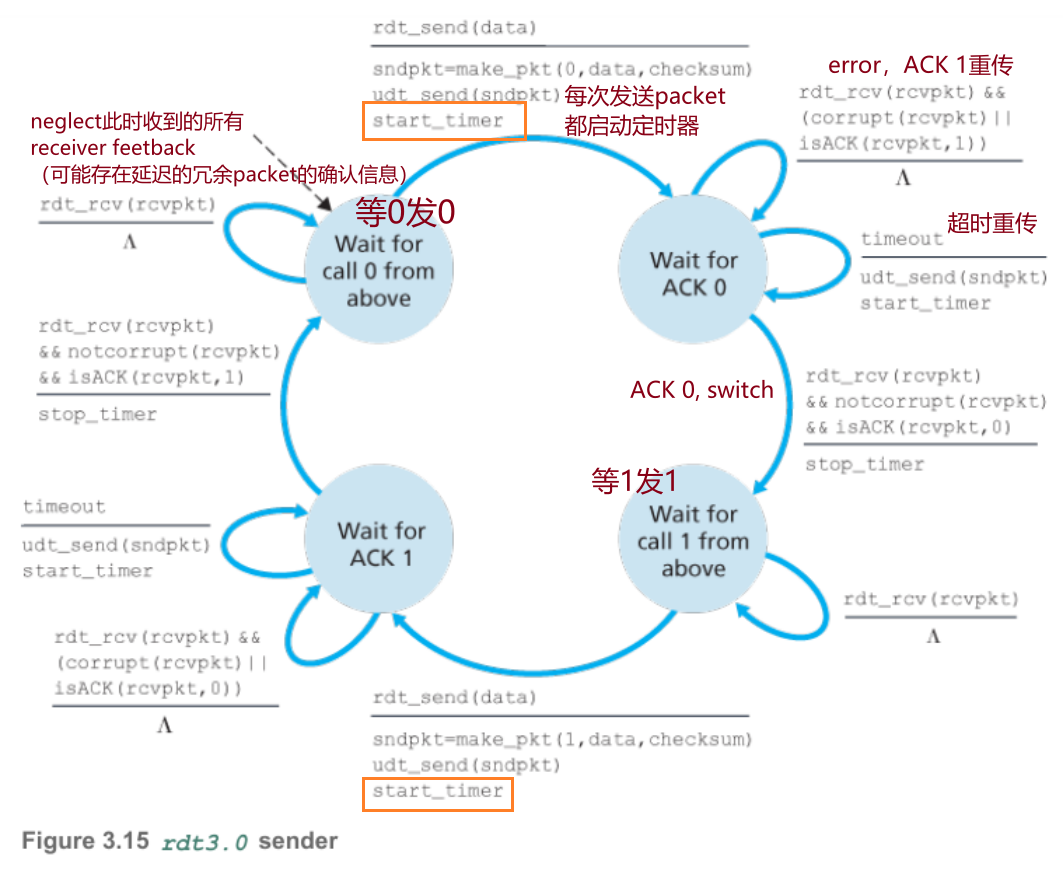
接收方与rdt2.2是一致的,只关心收到的packet,错误则传送与状态相反标号的ACK,其余情况传送与packet相同标号的ACK,只有与当前所在状态标号相同的时候向上层传输数据。
发送方每次发送packet都启动定时器,每隔一个cycle就重传,直到接收到正确的ACK,关闭定时器,切换到下一状态,等待上层再次调用,该过程中忽略所有可能延迟到达的receiver feedback。
由于01序号交替,也被称为alter-nating-bit protocol比特交替协议
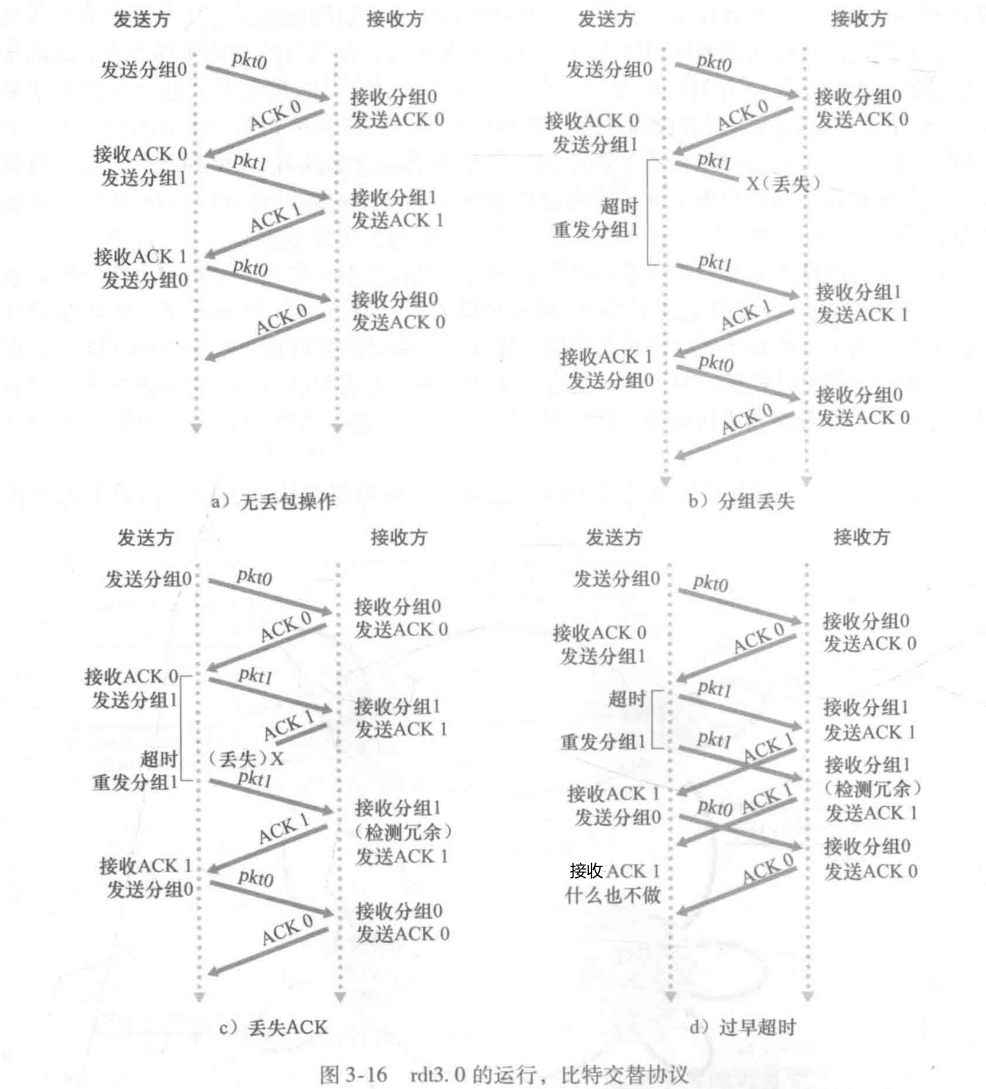
4.4 Pipelined Reliable Data Transfer Protocols
rdt协议的缺陷是由于其核心为停等协议,每次传输都至少要等待一个RTT,效率低下,因此采用pipeline技术,发送端能任意发送多个分组到信道中,毋须按照严格时序。
shortage:
- rdt3.0的比特交替分组编号方式(0-1)失效,需要增加编号范围
- 分组可能会失序到达,双方都需要建立缓冲区
分配序号:
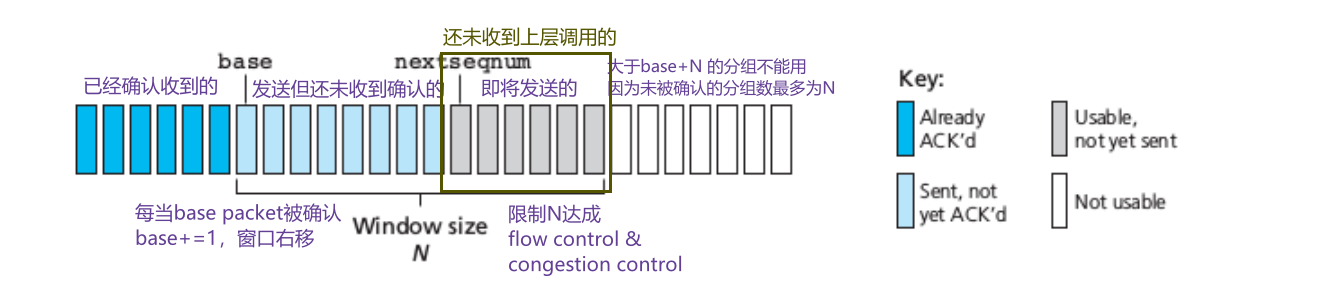
参数:
- N:这里的N不是固定的,$N=nextseqnum-base+1$,但有上限
base:最小未被确认packet的序号
- nextseqnum:下一个等待被调用发送的packet序号
序号范围:一般序号会承载在packet header的一个固定字段中,序号范围由字段大小k进行确定,为[0,2^k^-1]。当序号用完之后,进行取模运算,从头开始编号。由于序号是取模分配的,如果窗口长度N和序号范围太接近,在一个窗口中存在两个相同序号,产生冲突。对选择重传协议而言,窗口长度必须小于或等于序号空间大小的一半。
两种方式处理数据丢失、损坏、失序、超时:
- Go Back N,退回N步
- Selective Repeat,选择
4.4.1 Go Back N
初始情况下,base=1, nextseqnum=1。发送方要响应三个事件:
- 上层调用
- receiver feedback
- error,继续等
- ACK k,base=K+1,移动窗口
- 若所有分组已确认(也没有要发送的了),关闭计时器等待上层再次调用
- 若还有分组未确认,重启定时器
- time out,GBN协议重传所有已发送但未被确认(窗口内)的分组
发送方:
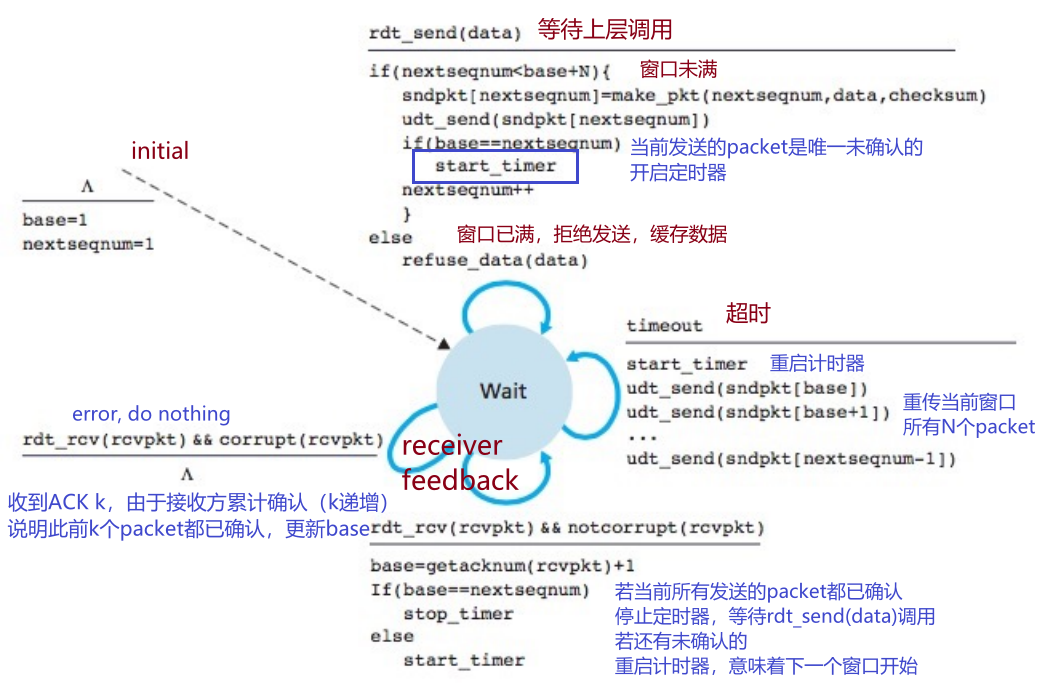
发送方只有一个全局timer,每次所有已发送packet已确认时停止,每次超时、base未确认,都会重启定时器。
接收方:
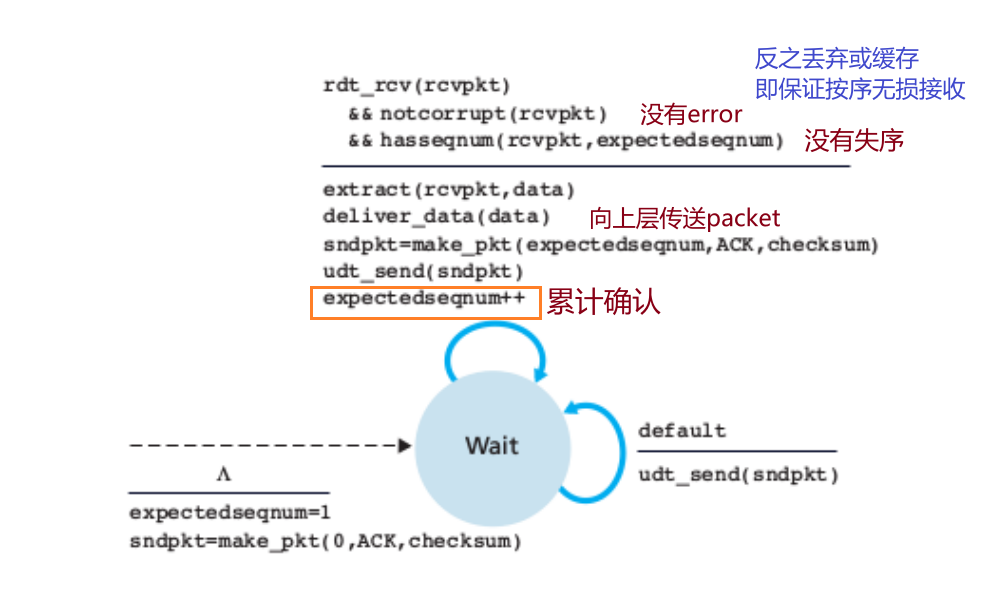
重传之后累计确认的问题:由于接收方按序接收,假设packet k超时,从它开始后面的数据都会被丢弃/缓存,无法确认,因此累计到的expectedseqnum也不会变,依然还是k-1,直到确认packet k开始。
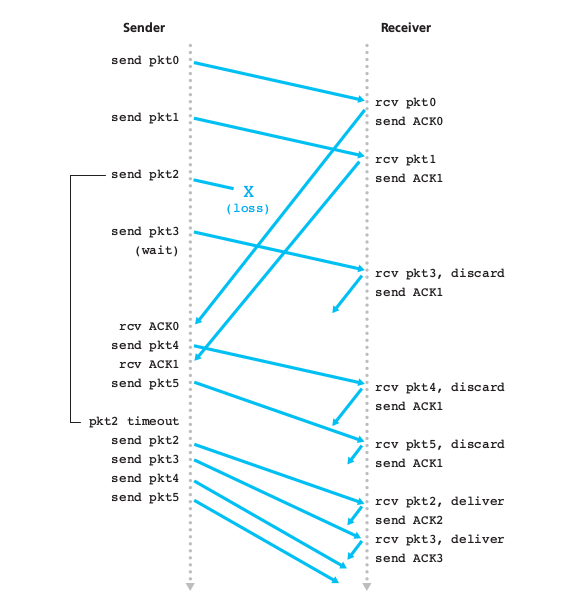
shortage:
- 一旦某个分组超时/丢失,就引起大量分组重传,成本较大
- 接收方的累计确认机制会丢弃乱序的分组,造成重传
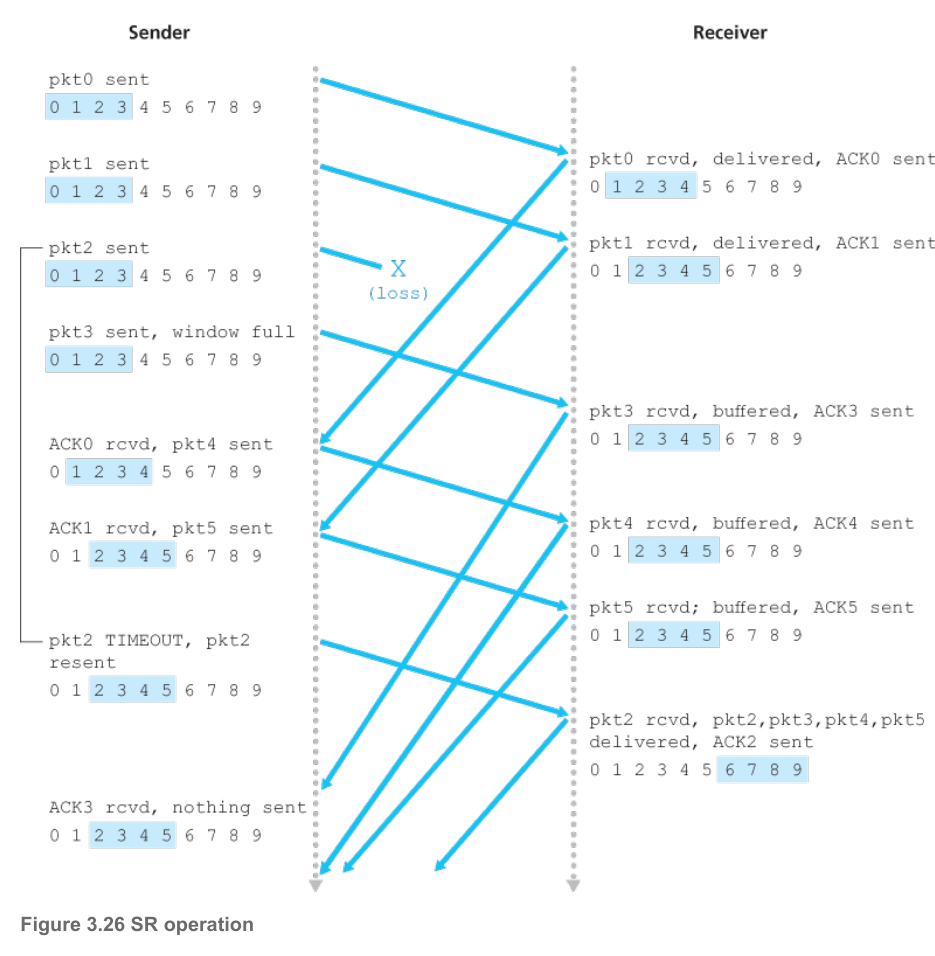
4.4.2 Selective Repeat
选择重传是对退回N步协议的改进,即发送方只会重传那些它怀疑在接收方出错(丢失或受损)的分组,而接收方将失序但正确的分组缓存起来,从而避免不必要的重传。相比Go Back N,其为每个packet维护一个定时器,超时未确认则重传。
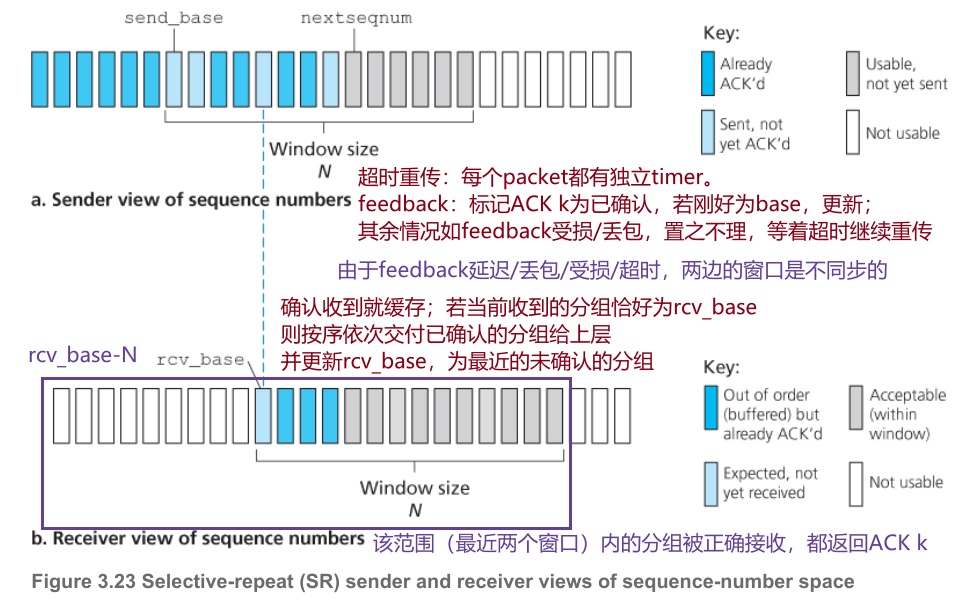
由于ACK也有丢包的可能性,每次接收方收到上个窗口[rcv_base-N,rcv_base)的packet,都返回ACK,防止发送方未收到ACK一直重传。
5. TCP(Transmission Control Protocol)
Conclusion:TCP的特征为面向连接(体现在3次握手)、全双工、点对点(多重广播)、双向传输。
TCP的连接管理:
- 3次握手:client开辟连接,发送SYN segment(SYN=1),server发送SYNACK segment(单独ACK不包含任何数据,不是捎带确认,该确认segment中会给予该SYN segment一个cookie,此时不开辟连接,防止SYN flood attack),client发送ACK segment,可能包含请求数据,收到后server开辟连接。
- 关闭连接:client发送FIN segment(FIN=1)请求关闭,server发送ACK确认后一段时间再发送FIN segment,client确认后,两端真正关闭连接。
TCP提供RDT、流控制、拥塞控制服务。
- RDT:发送方维持一个定时器,超时重传,并累计确认,收到冗余ACK就快速重传,无需等到超时。
- 流控制:在header中维持一个receive window(用最后读取、最后接收、最后发送、最后确认与buffer size来表示)。
- 拥塞控制:
- 通过cwnd控制速度;
- 丢包(超时/冗余ACK x3)视为拥堵,收到一个ACK则增大cwnd,pushy strategy;
- 拥塞控制算法:初始cwnd=MSS,慢启动(cwnd+=MSS,指数增长)、拥塞避免(cwnd+=MSS*MSS/cwnd,线性增长)、快速恢复(cwnd+=MSS,指数增长),只要丢包(timeout/duplicate ACK)ssthresh=cwnd/2且重传,超时则重启慢启动,冗余ACK则cwnd=ssthresh+3MSS,进入快速恢复,直到首次收到新的ACK,视为拥塞结束,进入拥塞避免。
5.1 Definition
Features
- connection-oriented: 3-way handshake
- full-duplex service
- point-to-point, multicasting
- bidirectional
MSS, MTU, TCP segment size
MSS(Maximum Segment Size)是指TCP协议中一个数据段(segment)能够承载的最大数据量(不包括TCP header,只是应用层所需data field),它是TCP连接双方在握手过程中协商得出的结果。
MTU(Maximum Transmission Unit)是指数据链路层协议中一个数据帧(frame)能够承载的最大数据量。
TCP segment size指的是一个TCP数据段的大小,它包括TCP首部和数据部分。发送方根据MTU的大小来调整MSS的大小,以确保发送的TCP数据段可以被正确地传输和接收。
TCP segment structure
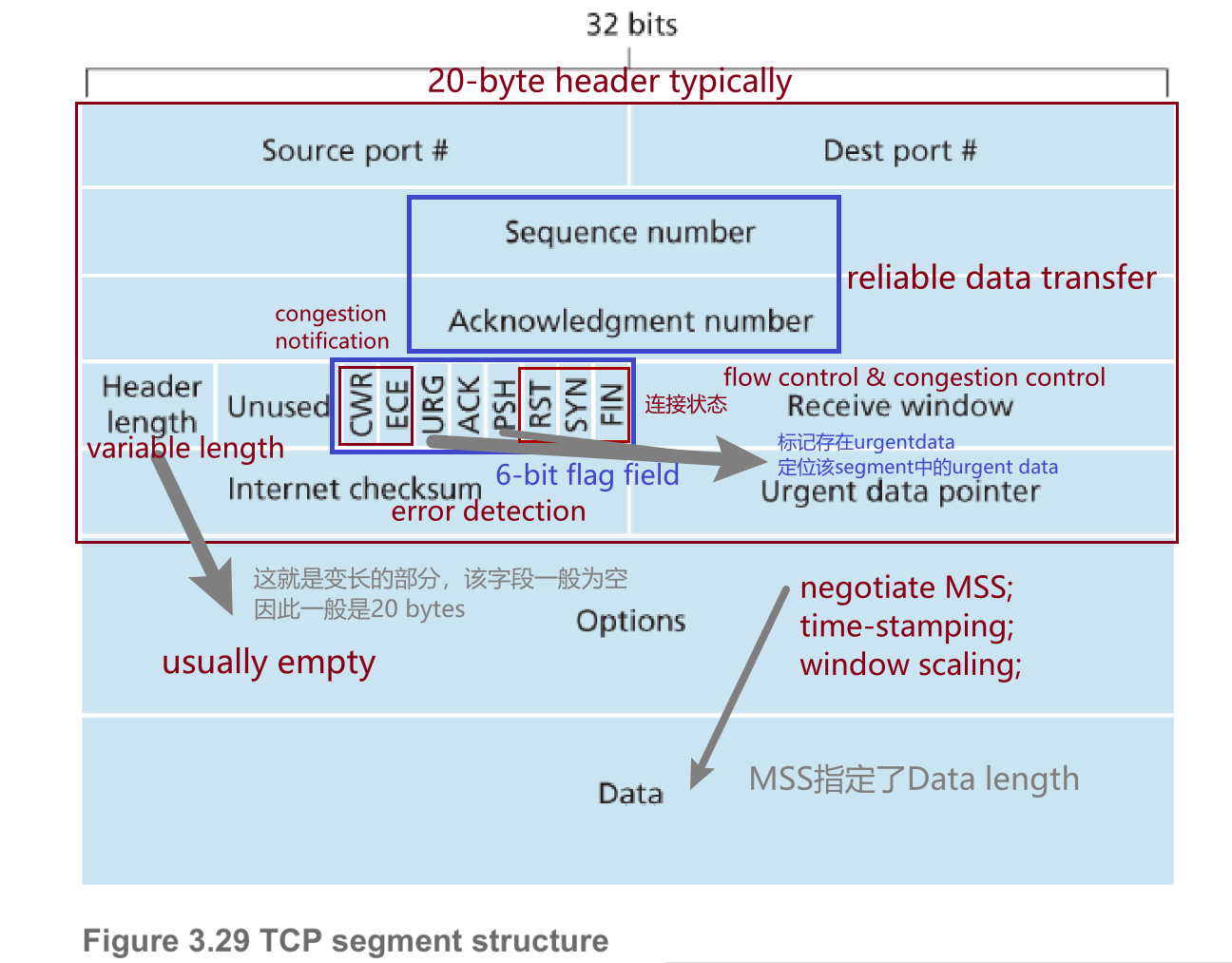
TCP将数据看作无组织但有序的字节流,为每个字节编号与累计确认来实现有序确认。
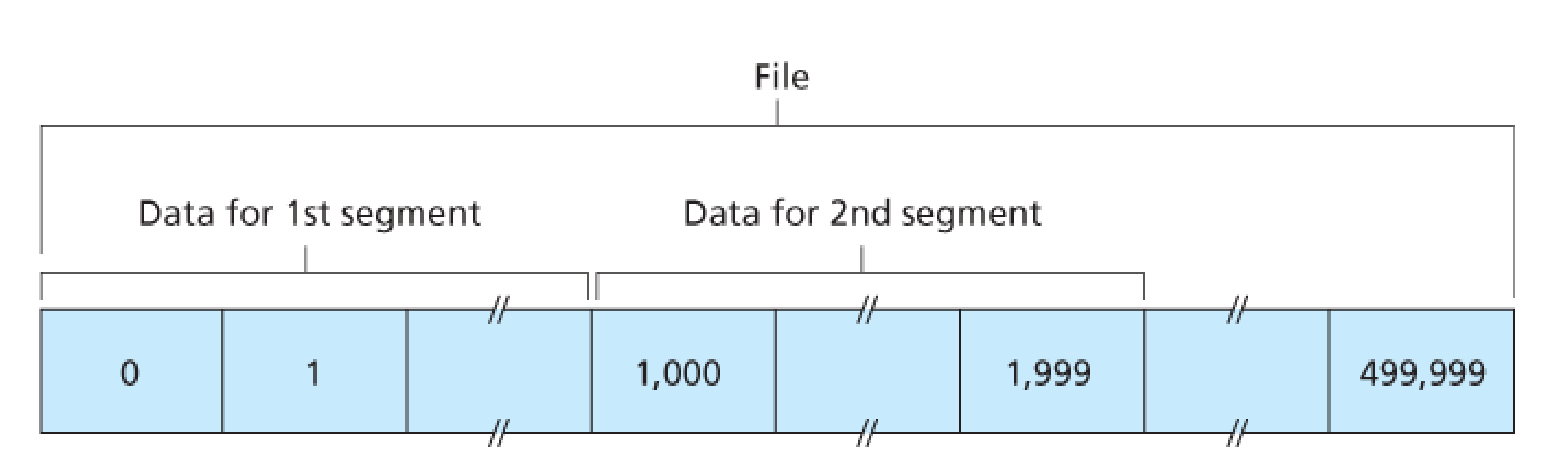
Sequence number: 为file data的每个字节编号,[0,MSS]为segment 1,[MSS,2MSS]为segment 2,以此类推。但一般会随机初始化序号,否则容易造成冲突。
acknowledgement number:TCP可能收到乱序的segment,此时会将其缓存等待重排。TCP接收方会在acknowlegment number field填入其需求的最小的字节编号,比如已收到[0,55],[100,155],其发送给发送方的segment中acknowlegment number为56。TCP采用累计确认机制(cumulative acknowledgements),每次只确认最小的缺失字节编号。
捎带确认:接收端发送数据时顺带地返回一个确认(ACK)信息,而不需要独立地发送一个ACK消息。发送端只能独立发送ACK消息。减少网络上的通信次数,提高网络效率。
以下情况接收端必须独立发送ACK:
- 接收端接收到SYN segment时,需要独立发送SYNACK作为第二次握手的响应。
- 接收端接收到一个受损segment时。捎带确认只能确认已经正确接收的数据。
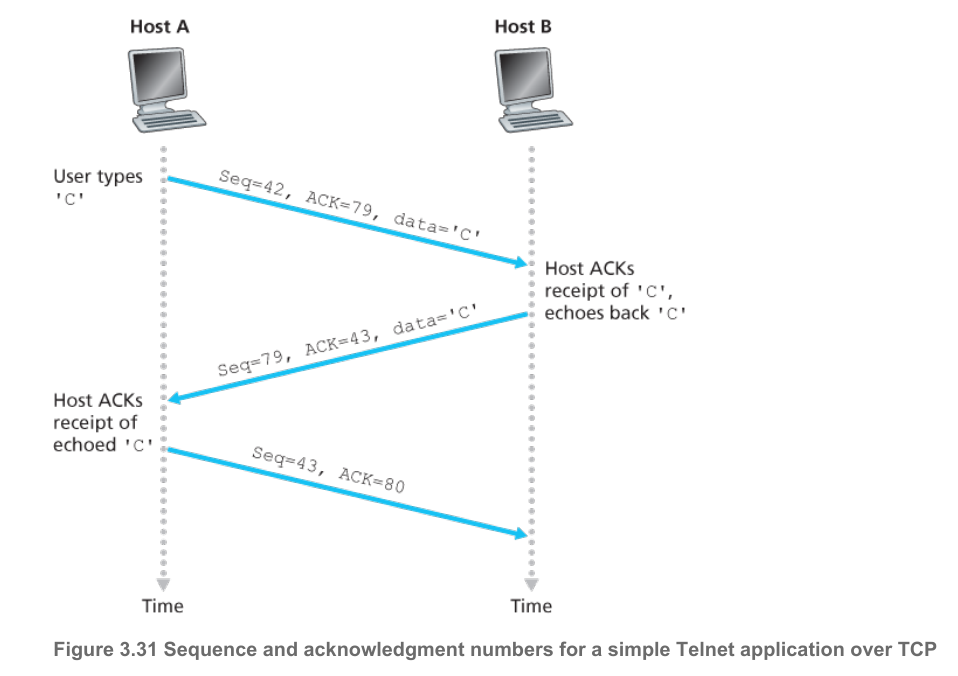
Telnet:用于远程登陆的应用层协议
5.2 RTT Estimation and Timeout
$EstimatedRTT=(1-\alpha) \cdot EstimatedRTT +\alpha \cdot SampleRTT $
TCP通过一定策略计算SampleRTT(不会采样每个segment),并计算其指数加权移动平均(EWMA),估计出EstimatedRTT。
| $DevRTT=(1-\beta)\cdot DevRTT+\beta \cdot | SampleRTT-EstimatedRTT | $ |
DevRTT是预测值与测量值差值的EWMA。
$TimeoutInterval=EstimatedRTT+4\cdot DevRTT$
出现超时后,TimeoutInterval应当加倍,以免即将被确认的后继报文段过早出现超时。但只要收到报文段并更新EstimatedRTT,就再次计算TimeoutInterval。
5.3 RDT service in TCP
assumption:发送方不受TCP流控制、拥塞控制的限制;数据长度小于MSS(不需要切割),且单向数据传送。
TCP在发送方部署一个single timer,发送方响应以下事件:
- call from above,从上层接受数据,若定时器未运行,启动定时器;
- Timeout,重传最小序号的未应答segment,启动定时器;
- receiver feedback,收到ACK k,TCP采用累计确认,这可以说明k以前的字节都已经收到,故更新base。若当前仍然存在未应答segment,启动定时器。
快速重传
duplicate ACK:假设接收方当前需求为segment y,接收方只要收到的segment k(k>y),就发送冗余ACK y,发送方只要收到3次ACK y,就快速重传y。此外,由于TCP采用累计确认,只要收到ACK k(k>y),就会在超时前重启计时器,无需重传segment y。
TCP不是GBN协议(不会重传一整个窗口),也不完全是SR协议(TCP可以有选择地确认失序报文段),可以被分类为其混合体。
5.4 FLow Control
用receive window来实现Flow Control。
- receiver:
- LastByteRead:应用从缓存中读取的最后一个字节编号
- LastByteRcvd: 最后一个放入缓存的字节编号
- RcvBuffer: total buffer size
- rwnd: receive window=RcvBuffer-[LastByteRcvd-LastByteRead]
- sender:
- LastByteSent
- LastByteAcked
$LastByteSent-LastByteAcked≤ rwnd$

当rwnd为0时,sender会一直继续发送单字节数据segment,这些segment会被receiver确认,直到确认segment中包含一个非0的rwnd。
5.5 Connection Management
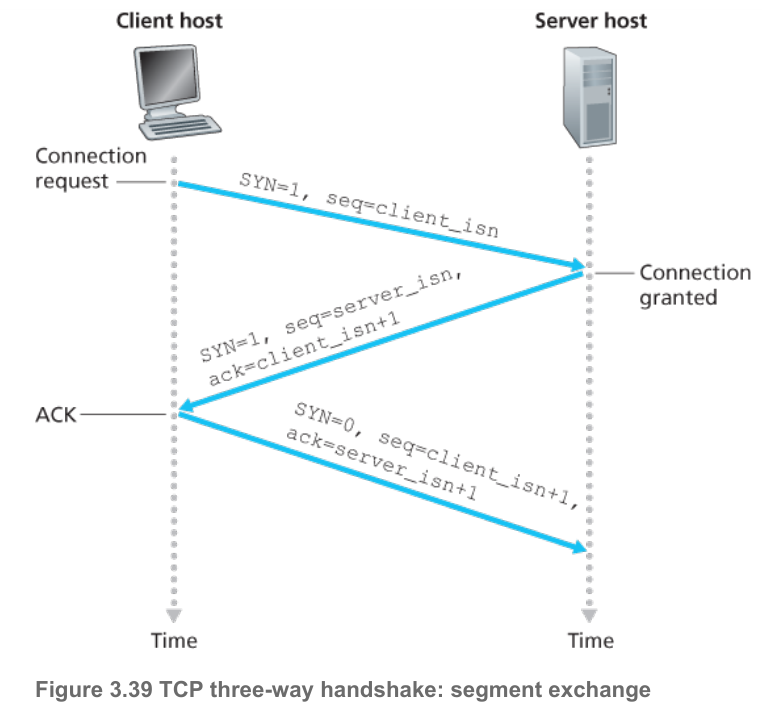
3-way handshake
- client TCP发送SYN segment,SYN=1,序号client_isn随机初始化
- server为该连接分配TCP缓存和变量,向client TCP发送SYNACK segment,SYN=1,ACK=client_isn+1,包含初始化的server_isn
- client为该连接分配缓存和变量,向server发送segment,SYN=0,ACK=server_isn+1,该segment可以负载data
close
- client发送close request,segment中FIN=1
- server发送ACK,再发送其终止segment,FIN=1
- client发送ACK,client TCP等待30s后终止,释放资源
- server收到ACK,server TCP终止,释放资源
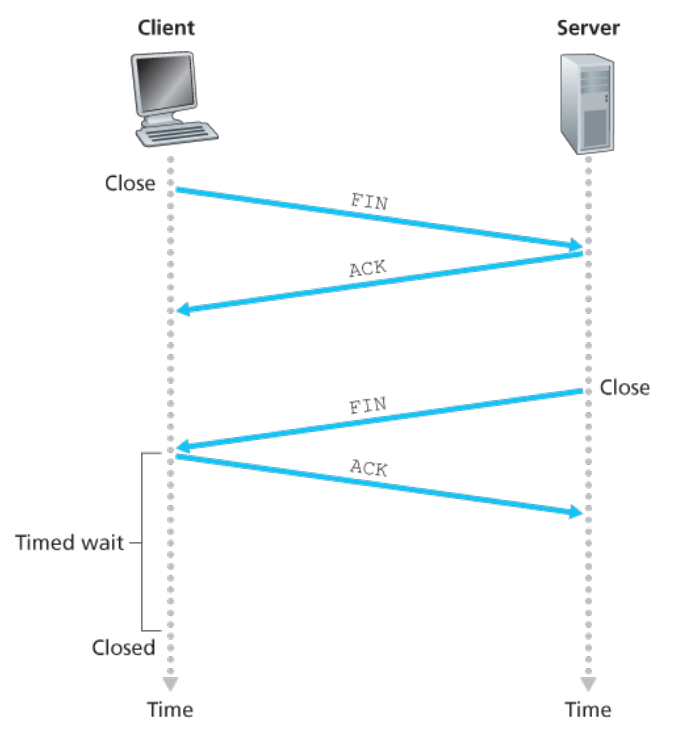
SYN flood attack - classic Dos attack
向服务器发送多个SYN segment,server会在第二次握手为其开辟空间,导致服务器连接资源殆尽
SYN cookie:收到连接请求时生成一个初始TCP序列号,与SYN segment的源地址有关,作为cookie,不开辟空间,发送含有该序列号的SYNACK segment;当client返回第三次握手的ACK segment,验证该ACK segment序号与SYNACK segment中的cookie值匹配,此时server才生成连接。
5.6 Congestion Control
根据【网络层是否为运输层拥塞控制提供了显式帮助】来分类:
- end-to-end,无关网络层,TCP采用这种方法
- 网络辅助的拥塞控制,routers向发送方提供显式反馈信息。
- routers-sender:choke packet
- receiver-sender:路由器标记packet中的某个field,收到flagged packet后,receiver通知sender,这种通知至少要经过一个RTT
TCP Congestion Control
TCP拥塞控制通过三个方面实现:
- TCP发送方能够限制发送流量的速率
- TCP发送方能够感知拥塞
- TCP发送方感知到拥塞时,如何应对
限制流量速率
变量:
- LastByteSent
- LastByteAcked
- cwnd,congestion window
$LastByteSend-LastAcked≤min{cwnd,rwnd}$
v=cwnd/RTT,通过调整cwnd的值,可以调整连接发送数据的速率
感知拥塞
丢包:timeout/3 duplicate ACK(4 ACK in total),视作拥堵,减小cwnd
ACK segment:TCP是self-clocking的,使用确认/计时来增大cwnd
带宽检测:只要收到ACK,一直增加cwnd,直到出现丢包,减小该速率,然后再次开始探测(增大cwnd),总之就是不停试探边界
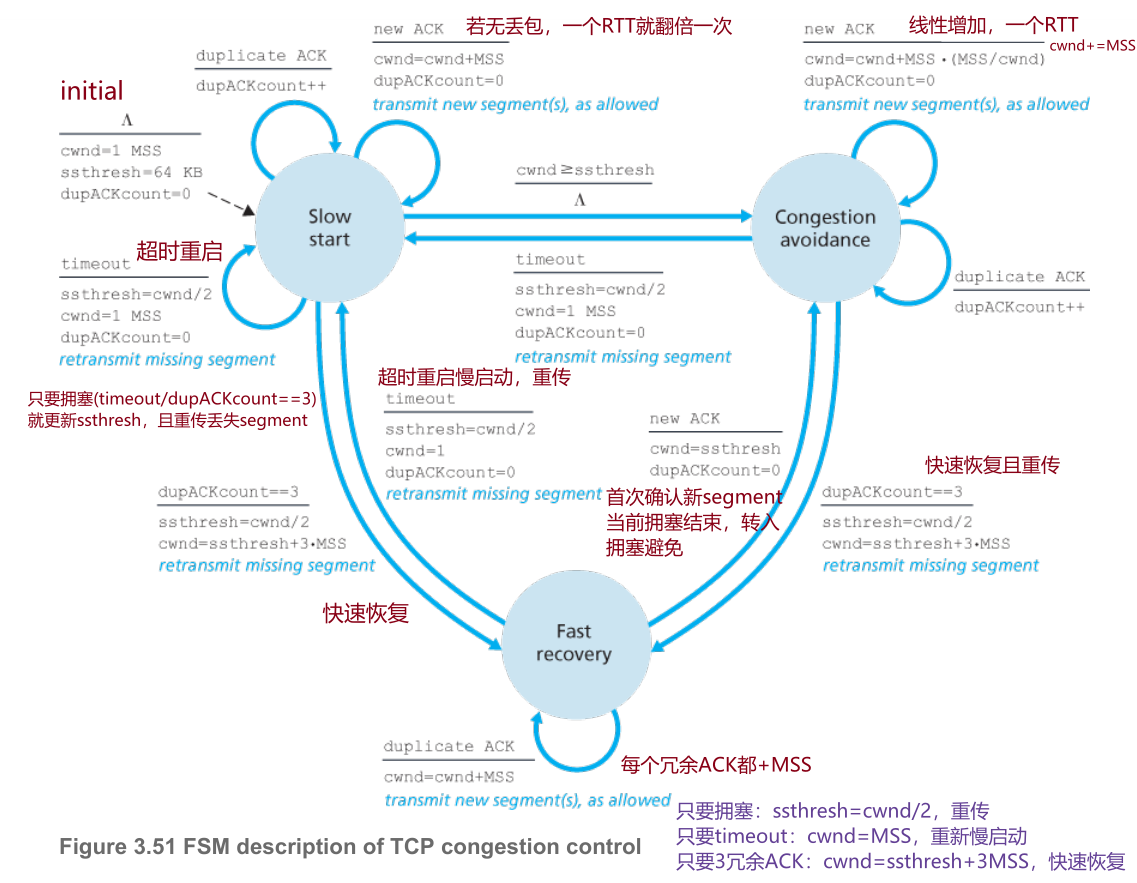
拥塞控制算法
- 慢启动slow-start(强制)
- initial:cwnd≤MSS,v=MSS/RTT
- 收到一个首次确认的ACK就翻倍,MSS*2^n^
- 若出现拥塞,更新慢启动阈值ssthresh(slow-start thresh)=cwnd/2
- 超时,cwnd重置为1MSS,重新开始慢启动
- 3 冗余ACK,TCP快速重传,cwnd=ssthresh+3MSS,进入快速恢复
- 当cwnd≥ssthresh,结束慢启动,进入拥塞避免
- 拥塞避免(强制)
- 每个RTT,cwnd+=MSS,线性增加;例如,对每个到达的ACK,cwnd+=MSS*MSS/cwnd
- 拥塞,ssthresh=0.5 cwnd
- timeout,cwnd=1MSS
- 三个冗余ACK,cwnd=ssthresh+3MSS,进入快速恢复
- 快速恢复(推荐)
- 收到ACK,cwnd=ssthresh,切换拥塞避免
- 拥塞
- 超时,ssthresh=cwnd/2,cwnd=1 MSS,重启慢启动
- 冗余ACK,cwnd+=MSS,快速恢复的主体
AIMD(Additive-Increase, Multiplicative-Decrease, AIMD),加性增、乘性减:TCP线性增加其cwnd,直到出现3个冗余ACK,cwnd减半,再开始线性增长,不断探测可用带宽
高度理想化的TCP稳态动态性模型:
$一条连接的平均吞吐量=\frac{0.75W}{RTT}$
W:当前cwnd
经高带宽路径的TCP:
$一条连接的平均吞吐量=\frac{1.22MSS}{RTT \sqrt{L}}$