
- 体系结构在大规模机器学习的应用
体系结构在大规模机器学习的应用
Introduction
随着对数据处理的规模与效率的需求发展,为了在软硬件之间取得平衡,从更底层的逻辑架构提高数据处理效率,计算机体系结构在与大数据、并行计算紧密相关的机器学习领域中得到广泛应用。恰当地选择和设计体系结构可以提高机器学习模型的性能,并使其能够在给定的资源限制下最大化其表现。
目前,机器学习与体系结构的交叉领域面临着许多挑战,研究人员提出了可能的解决方式:
- 大数据问题:随着数据量的增加,训练和运行机器学习模型所需的计算资源也在增加。分布式体系结构可以帮助解决这个问题,例如使用分布式训练来加速模型的训练时间。对于高维数据,则可以借助机器学习优化编译器AStitch,拓展了新的多维优化空间。
- 模型复杂度问题:随着模型复杂度的增加,训练和运行模型所需的资源也会增加。结构化体系结构可以帮助解决这个问题,例如使用模型压缩技术来减小模型的大小。
- 隐式偏差问题:机器学习模型可能会在训练数据上过拟合,从而导致对新数据的不佳预测。结构化体系结构可以帮助解决这个问题,例如使用正则化技术来限制模型的复杂度。
本次文献综述将围绕A Software-defined Tensor Streaming Multiprocessor for Large-scale Machine Learning(用于大规模机器学习的软件定义张量流多处理器), AStitch: Enabling a New Multi-dimensional Optimization Space for Memory-Intensive ML Training and Inference on Modern SIMT Architectures(AStitch:为内存密集型ML训练和现代SIMT架构推理提供新的多维优化空间)两篇论文进行分析总结。之所以在给定论文中选定这两篇论文进行综述,是由于其主题较为接近且相似。这两篇论文针对机器学习中数据处理与模型训练的效率瓶颈,分别提出了一个张量流多处理器软件调度网络,以及AStitch,一个针对内存密集型机器学习的优化编译器。
A Software-defined Tensor Streaming Multiprocessor for Large-scale Machine Learning
目前,大规模机器学习模型的训练需求是双重的。
- 在网络层面上,训练ML模型的网络需求通常需要数据并行性(弱缩放),这与使用流水线模型并行性(即并行性)对同一模型进行推断不同,后者需要强缩放。
- 在计算层面上,大型模型的计算需求通常需要大量内存资源来存储模型参数、常数和梯度,以适应每个处理元素(Processor Element,PE)的可用内存,并且在处理元素之间实现负载平衡。因此,在传统的CPU或GPU多处理器中,内存和网络资源在处理元素之间动态共享,这是不确定性的来源。
基于该现状,该论文面向大规模机器学习,针对当前大规模机器学习模型训练的两难之处与需求瓶颈,提出了一种新型的、商用的、向外扩展张量流多处理器(Tensor Streaming Multiprocessor, TSP)的软件调度系统结构。软件定义的多TSP系统利用软件调度的高基数的蜻蜓拓扑网络和ISA “runtime deskew” 指令支持保持同步的假象,支持锁步系统,将单个TSP的确定性扩展到整个多TSP网络。论文从多TSP网络的拓扑结构、软件静态调度策略、同步、路由、流控制和容错等方面较为完备地描述了该系统架构,解决了传统多处理器中的不确定性难题,并赋予了网络可扩展性。
确定性执行与向外扩展的保证
确定性执行提供了一种机制,使得使用给定输入数据集进行的计算始终在限定时间内产生一致的输出。利用确定性执行可以保证软件行为的可预测性和可重现性。
向外扩展性在集群系统(多个节点组成的系统)中主要以水平扩展方式(指增加节点的方式)来进行,突破单机限制,通过将多个低性能的机器组成一个分布式集群来共同抵御高并发流量的冲击,比如向原有的web、邮件系统添加一个新机器。
根据该TSP网络向外扩展(Scale Out)、确定执行(Deterministic)系统架构的需求定位,在硬件上,该系统将基于蜻蜓拓扑的系统层次组织,以及处理元素之间芯片到芯片(C2C)链路的基本属性,保障其可扩展性(scalability)。在软件上,TSP的编程模型是基于静态调度策略,为参数和指令文本提供220 MiBytes的本地存储。每个TSP都使用生产者-消费者流编程模型进行编程,该模型允许将功能单元链接在一起。TSP的功能单元被组织为320元SIMD(单指令多数据)指令执行到能片组(functional slices)包括一组20个瓷砖,每个瓷砖对数据执行16路SIMD计算。
网络拓扑结构
蜻蜓拓扑(Dragonfly Topology)是由John Kim等人于2008年提出的一种网络拓扑结构,被广泛地应用在高性能计算网结构上。Dragonfly的结构有三个层级:路由器(Router)、组(Group)、系统(system),它的拓扑结构一般由以下这些参数描述:
| 参数 | 描述 | 参数 | 描述 |
|---|---|---|---|
| N | 网络中的终端数 | p | 每个路由器连接的终端数 |
| a | 每个组的路由数 | k | 路由器的接口数 |
| k’ | 每一组的有效接口数 | h | 每个路由用于与其他组连接的频道个数 |
| g | 系统内组个数 | q | 输入端口队列长度 |
| qvc | 单个输出虚拟通道(VC)的队列深度 | H | 跳数 |
| Out~i~ | 路由i号输出端口 |
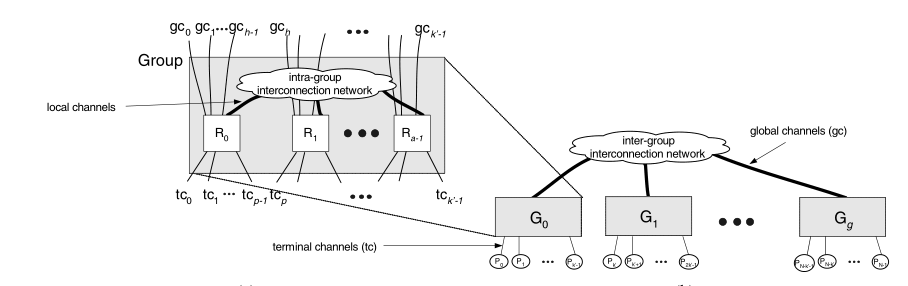
如图1所示,最底层的每个路由器与p个终端链接,并拥有a-1个与组内路由器通信的本地频道(Local Channel),以及h个与其他组路由连接的全局频道(Global Channel),由此可以计算出每个路由器的接口数k=p+h+a-1。在组(Group)的层面上,每组连接着ap个终端,并拥有ah条全局频道的连接(ah connections to global channels),可以将一个组抽象为拥有k’=a(p+h)个端口的虚拟路由器(virtual router),由于其拥有非常高的路由数因此在系统层面的网络上可以拥有很短的全局网络直径(global diameter)^[1]^。
在Dragonfly拓扑中组内路由的连接方式可以根据实际需求进行调节。组内的路由方式可以是任意的,如在Dragonfly+拓扑中组内使用胖树的结构。
基于Dragonfly拓扑,论文提出的网络结构具有以下特征:
- 低网络直径:观察到的总通信延迟和方差随着网络跳数的增加而增加。因此,减小网络直径可以减少网络延迟(跳数)以及降低网络成本。
- 打包结构拓扑:互连网络的拓扑结构主要由系统封装层次结构所施加的封装约束驱动。
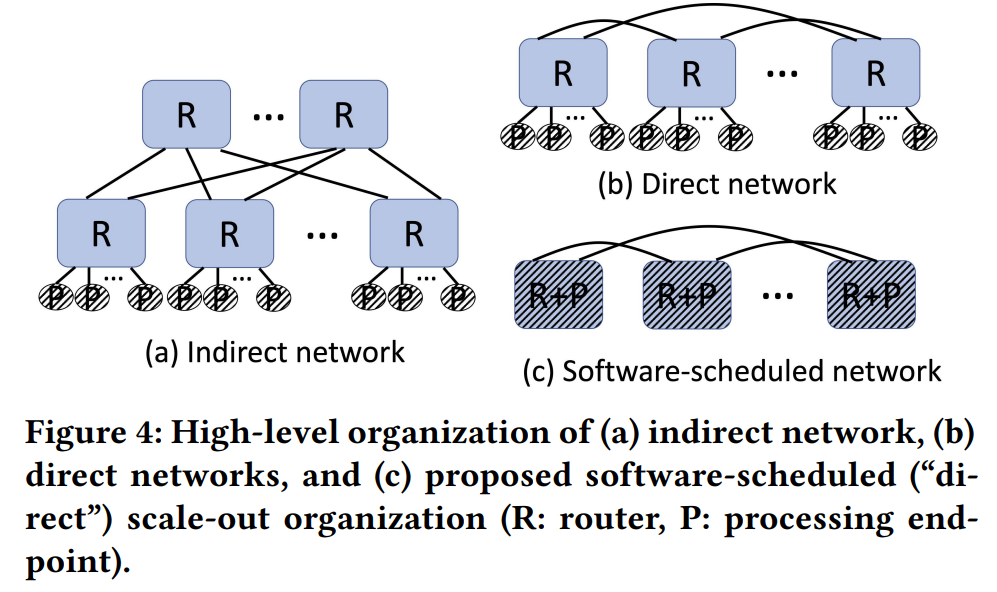
- 使用直连网络:如Figure 4,将端点processing point与router相连,直接连接tsp来创建它们的通信结构;减少indirect中由于引入路由器与交换机及其动态调度与排队的不确定性因素。
![image-20230114170855579]()
同步机制
通过分布式系统的同步机制,硬件将确定性执行的保证从单个TSP扩展到多TSP系统。同时,该同步机制也是TSP系统向外扩展性的保证。
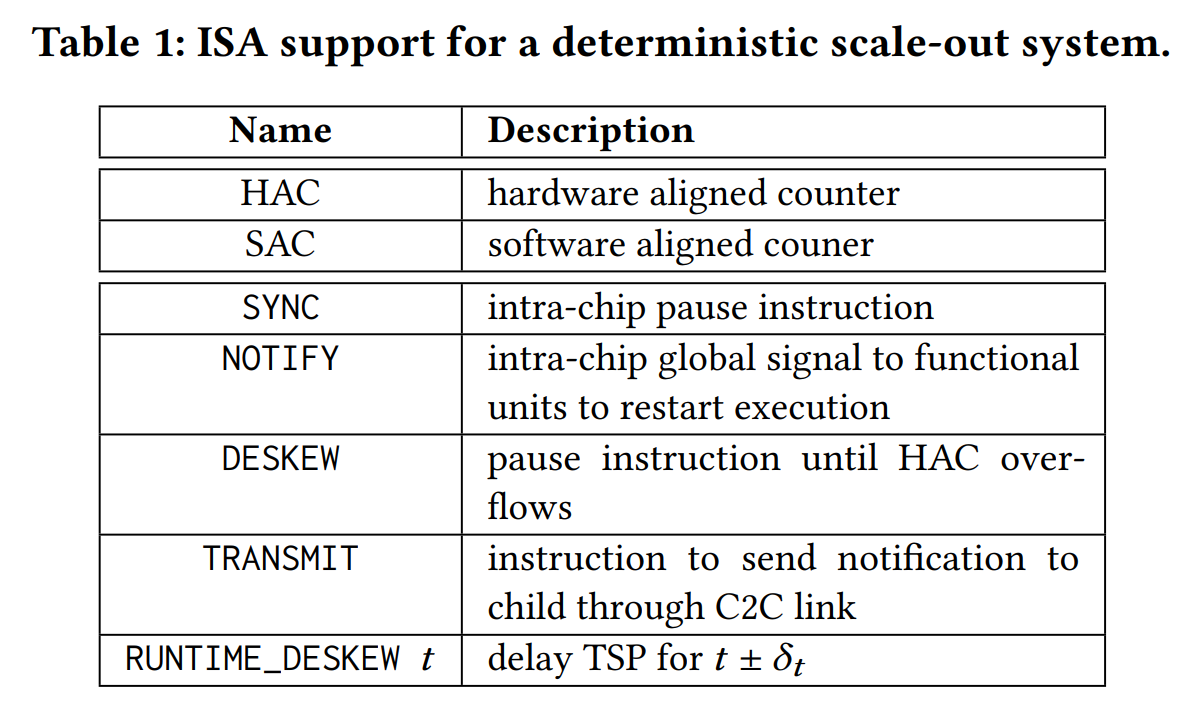
同步TSP网络涉及硬件和软件机制的组合。根据Table 1依次介绍ISA架构是如何支持确定性执行与向外扩展的:
- HAC指令:每个TSP维护一个自由运行的内部硬件对齐计数器(HAC)。
- SYNC和NOTIFY指令:提供了一个芯片范围的同步机制,它依赖于共享时钟和完全确定的控制传播路径。公共HAC引用可以通过以下方式组合在整个系统中提供共享时钟的假象,因此,这实际上是一种模拟同步机制。
- DESKEW指令:允许我们将程序执行与本地的HAC对齐,确保分布式计算可以相对于HAC epoch边界开始,该边界是网络中TSP端点之间的共享参考时间。
- SAC指令:TSP提供了一个额外的软件对齐计数器(SAC)来允许TSP在计算期间重新同步,以保持独立TSP端点之间的累积漂移在允许的公差范围内。
软件调度网络( Software-scheduled networking,SSN)
TSP体系结构的一个基本特征是它的确定性数据路径。所有指令的执行延迟都是静态的(在编译时),因此通过ISA(指令集体系结构)向编译器公开。多TSP网络正是通过软件调度网络(SSN)来保证负载平衡的确定性。
网络流量模式
要启用SSN,需要知道通信或网络流量模式。对于multi-TSP目标的大多数工作负载,在空间和时间上的通信模式都是在编译时通信本身先验已知的。因此,SSN可以利用ML模型的静态计算图和流量模式的先验知识,做出最优的路由或“调度”决策。
SSN实现了跨处理元素划分模型,同时考虑模型并行性(即跨tsp分布不同层)和数据并行性,以利用跨集群的小批并行性。模型分解由编译器自动执行,以便在所需数量的TSP元素之间自动缩放工作负载。编译器将工作负载划分为更小的子任务,并将它们映射到负责执行它们的各个tsp。多tsp系统利用蜻蜓的路径多样性,在可用链路上传播所提供的流量,这就保障了负载平衡的确定性。
调度策略
与传统的调度策略相比,以路由算法为例,路由算法确定消息在网络中所经过的路径,通常在硬件中使用查找表来实现,通过检查数据包的目的地节点为每个传入数据包提供简单的输出端口映射。相比之下,多tsp系统通过分别在源节点和目标节点上编排发送和接收指令序列,显式地控制和调度网络中的逐跳路径。假定所有数据移动都可以静态推断,编译器将基于跨时间和空间的全局信息编排数据移动,以消除共享输出端口的冲突。
流控制
在该多TSP网络中,根据论文描述,研究人员在TSP的节点之间与之内建立C2C(芯片-芯片)连接,作为在网络上传输数据的纽带。
具体来说,当一个张量在网络中一跳一跳地流动时,我们使用每个TSP上的本地SRAM存储来为张量的各个向量提供中间缓冲,这样,一个向量就是流量控制单元(flit)。
在硬件上,在多TSP网络中,除了C2C逻辑和TSP核心时钟边界之间的接口处有浅缓冲区外,没有数据中心网络中常见的传统缓冲区。这样避免了传统体系结构中虚拟/物理通道与缓冲区造成的拥堵与重发等调度所需的时间。相比之下,流控制是从软件层面进行的,通过软件调度网络防止路由死锁,减小了额外虚拟(物理)通道的复杂性与时空间成本。
前向纠错
在容错率上,TSP体系结构使用的是前向纠错方法,为了保持确定性,就地纠正任何传输错误,标记任何需要运行时软件重放的关键错误。具体做法为用网络链接上的FEC和整个TSP的内存系统、数据路径和指令缓冲区的单次纠错和双次错误检测(SECDED)来防止这些关键错误。
评析与总结
论文最后通过软件栈、分布式矩阵乘法、常见机器学习模型的训练对系统的性能进行了评估,作为对系统可行性与优越性的证明。
论文提出的TSP体系结构,是在前人研究的基础上,对网络结构的一次创新。在相关领域的历史上,为了利用蜻蜓拓扑的路径多样性,研究人员已经提出了不同的全局自适应路由算法。然而,先前的工作都集中在基于硬件的蜻蜓网络,该论文则提出了基于软件调度的蜻蜓网络,通过改进后的直连网络结构与静态调度策略,最终在软件层面实现了确定执行的蜻蜓网络。
我还注意到,论文提出的TSP体系结构使用的是芯片-芯片接口。C2C 接口的设计目的就是在移动应用处理器和调制解调器之间提供高效率的无缝接口,大幅降低成本,缩减印刷电路板 (PCB) 面积。有了高带宽低时延 C2C 接口,我们就不再需要调制解调器 DRAM,从而可节省金钱成本与空间资源。更重要的是,这种分离式架构可将两大领域的优势完美地结合起来,为移动产业带来最理想的创新环境^[2]^。
在当前论文工作中,我认为可能具有的缺憾之处在于网络的流控制。论文提到,为了减小了额外虚拟/物理通道的复杂性与排队调度的不确定性,该TSP体系结构缺乏硬件流量控制;因此,流控制只从软件层面进行,通过静态调度策略防止路由死锁,并保障确定性。这意味着,在数据规模过大时,调度算法可能造成额外的内存资源占用或传输信息的缺失或错时。然而,在谈论计算性能时一向是时间复杂度与空间复杂度的相互转换,研究人员也一定考虑了这点,才做出将硬件流量控制剔除的选择。故而我认为,也许可以在此处实现软硬件流量控制相结合,或进一步优化调度算法。
综上所述,该TSP体系结构为大规模并行机器学习的训练提出了一个优秀的网络结构,围绕该领域的网络需求与计算需求,实现了数据并行性与模型并行性,借助一定的调度策略将模型分离映射到对应的内存资源中,实现了确定性的负载平衡。其特色之处为软硬件结合,针对两个层面进行了改进,其一是确定性,该体系结构使用的软件调度网络具有显式的流量模式软件控制及其整个网络数据包的总顺序。其二,从降低通信成本的方面,它实现了TSP端点之间的确定性通信,消除延迟方差。
AStitch: Enabling a New Multi-dimensional Optimization Space for Memory-Intensive ML Training and Inference on Modern SIMT Architectures
机器学习模型通常包括两种类型的操作:
- 计算密集型操作通常由重型计算内核组成 ,例如GEMM/GEMV和卷积计算;
- 内存密集型操作通常受内存带宽的限制,例如按元素(element-wise)和减少(reduce)操作。
- 按元素(element-wise)操作:在一个按元素排列的操作中,各元素以按元素 排列的方式被独立处理。按元素计算的运算可以进一步分为轻型按元素计算的运算和重型按元素计算的运算。前者执行较轻的计算,如加和子,而后者执行明显更昂贵的计算(如tanh, power,和log)。
- 减少(reduce)操作:一个减少操作将一个张量作为输入,并还原其一个或多个维度。如果在一个维度上减少元素在内存中是连续的,则称为行还原;否则称为列还原。
论文揭示,在最近的机器学习模型中,内存密集型计算是一个比重不断上升的性能关键因素。其面临着如下的两难境地与挑战:
- 大量冗余计算造成内核占用率高,将冗余计算融合(fusion),维度过高的计算是昂贵的。这种复杂的两级依赖关系(运算符级别、操作进程层面)与及时性需求(Just in Time,JIT)相结合,加剧了训练/推理的低效率。
- 现实世界生产工作负载中的不规则张量形状,导致了模型的低并行性。
基于该背景,论文提出AStitch,一个机器学习优化编译器,为内存密集型ML计算打开了一个新的多维优化空间。针对以上两个挑战,AStitch分别从两个方面提出了改进方法:
- 多重运算器缝合方案实现了分层的数据重用,能够有效地将任何运算器“缝合”在一起,而没有大量的计算冗余。论文用“缝合”来区别提出的的高级融合技术与现有的ML编译器融合方法:其对当前融合范围的扩展是将当前工作所实现的许多小型和基本的融合“缝合”成更大和更广泛的融合。
- 提出了自适应线程映射技术,其基于一种在GPU执行的SIMT(单指令多线程)特性的任务打包和拆分方法,以适应性地处理各种张量形状,并产生适当的线程映射时间表,以最大限度地提高硬件利用率和平行度
多重运算器缝合方案
论文抽象出四种算子拼接方案,涵盖了从依赖性、内存层次和并行性共同考虑的所有依赖情况。
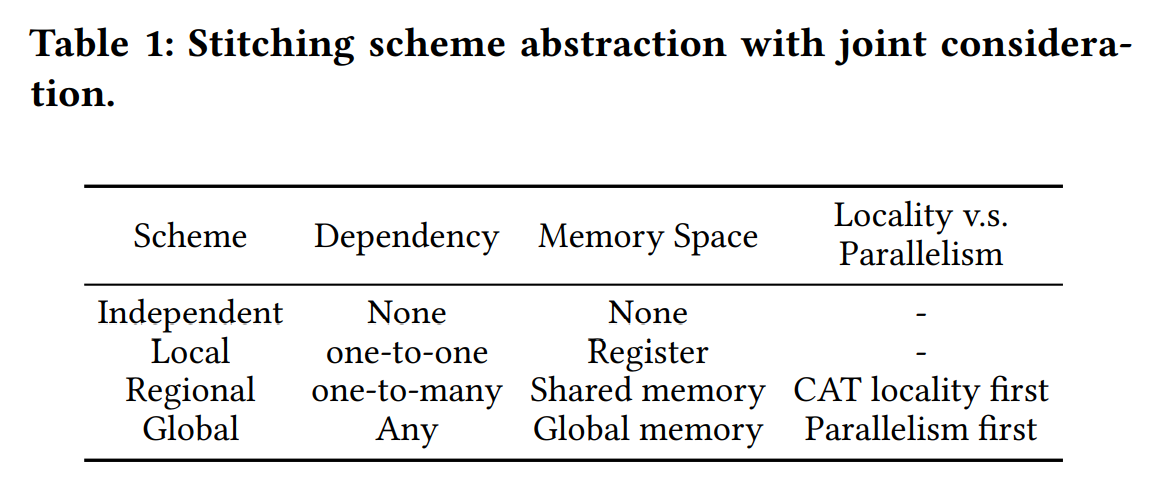
如Table1所示,各方案为:
- 独立方案代表相互独立的运算符。
- 本地方案代表相邻的运算符,具有元素级的一对一依赖(即元素级的方式),中间数据被缓冲在每线程寄存器中。这里线程级的数据定位得到了保证。这两种方案被最先进的设计所采用。
- 区域方案表示一对多的元素级别的依赖性。
- 全局方案是为了应对任何复杂的依赖关系,中间数据被缓冲在全局内存中。由于这是一个面向并行的方案,所以没有定位要求(全局内存对所有线程都是可见的)。
Astitch会根据操作者的特性来决定局部性和并行性之间的权衡(即局部性与全局性)。
Astitch实现了跨内存层次(即寄存器、共享内存和全局内存)的两级数据(元素级、操作员级别)重用,以消除融合的困境。
- 在Astitch中,对于一对多的元素级依赖关系,生产者对每个数据项只处理一次,不会产生多余的计算。其结果可以保留在GPU共享/全局内存缓冲区,供其消费者在区域/全局缝合方案中重复使用。
- 对于一对多的操作者级依赖关系,Astitch只处理一次生产者,并将其结果存放在缓冲区,供其多个消费者重用。对于本地缝合方案,待重用的数据被维护在寄存器上,而对于区域/全局内存,数据被维护在共享/全局内存上。
基于GPU执行的SIMT特性的任务打包和拆分方法
论文提出基于GPU执行的SIMT特性的任务打包和拆分方法,以适应性地处理各种张量形状。值得注意的是,受到不规则张量形状影响的主要是减少(reduce)操作,这是内存密集型计算中最耗时的操作。
任务打包
任务打包包括两个方面:水平和垂直。
- 横向打包是将多个小块打包,每个小块处理一行的还原,打包成一个大的线程块。
- 垂直打包是将多个线程块的任务打包成一个,以减少块的数量。这有助于将多个线程块打包成一波,以满足全局屏障的要求。
任务拆分
任务拆分是将一个线程块内的任务拆分成几个线程块,以增加块的数量,以防因块的数量少而造成利用率低的问题。
自动编译器优化设计
论文将以上方法嵌入编译器中,设计了一个自动编译器,能在一定程度上缓解内存密集型计算面对的计算与及时性(JIT)需求困境,也即是AStitch。
AStitch主要完成的工作是确认缝合方案。其步骤如下:
主导性识别和操作分组
Astitch只需要确定几个关键运算符的线程映射,然后将其传播给所有其他运算符。我们将这些关键运算符命名为主导运算符。AStitch首先确定几个成为主导运算符的候选者,并最终确定具有主导合并的最终运算符。
自适应线程映射和时间表传播
AStitch为每个主导操作生成并行代码,并在相应的组内传播线程映射计划。通过这种方式,我们得到了所有操作者的线程映射时间表。
张量形状适应。AStitch根据张量形状和硬件资源,根据上述的任务打包与拆分方法,自动为主导操作应用任务打包和拆分。以行缩减为例,如果要缩减的行数小于每波允许的块数,且每行包含大量的数据项(即大于1024),则AStitch会对行进行分割以增加并行性。
最终确定
AStitch在最后一步确定了主导和次主导的行动。减少操作会优先考虑并行性,因为它们需要更多的计算。因此,减少(reduce)操作主导的组将执行通过的块定位检查,而不调整其线程映射。另一方面,由于其低成本的计算,按元素(element-wise)操作通常优先考虑位置性。因此,由它们主导的组执行主动的块检查,以实现更多的块级定位。
评析与总结
论文最后使用单个NVIDIA V100 GPU为设备,用AStitch实现了具有代表性的机器学习模型,如BERT等,并给出了详细评估结果。结果显示,AStitch的速度比最先进的编译器高2.73倍,作为AStitch优越性的证明。根据论文所说,AStitch已被部署到一个生产集群中,并在一周内为70,000个任务节省了约20,000个GPU小时。这表明了Astitch的稳健性。
目前许多机器学习编译器的优化主要针对计算密集型操作,而对内存密集型计算的性能问 题关注有限。然而,根据该论文发现,近来在机器学习领域,内存密集型计算的性能比重正在上升,因此,论文的研究人员将提高内存密集型计算的性能作为基础动机。在相关工作中,存在一些编译器将融合优化应用于内存密集型的操作,但这些工作缺乏解决复杂的依赖性问题,并且存在融合不足的问题。 AStitch解决了这个问题,并在以前的工作基础上扩大了融合的范围,这也是其区别于相关的历史工作的特色之处。
AStitch作为一个机器学习优化编译器,具有如下优势:
多维:它在考虑多维优化目标的同时,系统地抽象了四种算子缝合方案,用新颖的分层数据重用处理复杂的计算图依赖,并通过自适应线程映射有效地处理各种张量形状。
- 可移植性:虽然AStitch是一个独立的编译器引擎,但其基本思想可以普遍应用于其他ML框架和优化编译器,可以移植到任何版本的TensorFlow。
- 高性能:解决了内存密集型ML计算的两个主要性能问题:效率低下的融合和输入、不规则的张量形状。
综上所述,论文提出分层数据重用技术来解决复杂的依赖关系,以扩大融合范围,减少非计算开销。论文提出了自适应线程映射技术来处理不规则张量形状的问题。结合这些技术,论文开发了一个名为AStitch的JIT编译器,将这些优化与高可用性相结合。可以说,AStitch填补了机器学习编译器中一个长期被忽视的空白。
结语
本次课程报告分析总结了两篇能够体现体系结构在大规模机器学习中应用的论文文献,A Software-defined Tensor Streaming Multiprocessor for Large-scale Machine Learning(用于大规模机器学习的软件定义张量流多处理器)关注机器学习模型的网络需求与计算需求,针对对并行性与确定性的保证,提出了TSP(Tensor Streaming Multiprocessor)系统结构。而AStitch: Enabling a New Multi-dimensional Optimization Space for Memory-Intensive ML Training and Inference on Modern SIMT Architectures(AStitch:为内存密集型ML训练和现代SIMT架构推理提供新的多维优化空间)则关注机器学习中的内存密集型计算性能,提出了一个自动编译器优化设计AStitch。
经过这两篇文献的阅读,可以对机器学习目前的发展图景与瓶颈有一个较为清晰的认识脉络。最首要的是,机器学习具有大规模数据与高效的需求,一切挑战都以计算性能为基点。
通过提高数据与模型的并行性,可以提高计算性能,也便于在支持并行的硬件设备(如基于GPU的CUDA)上运行,由此在这一分支上引出若干条支线:
- 软硬件的接口设计,包括支持并行式计算的网络拓扑结构,及运行在该网络上的软件调度策略;对此,论文提出了基于软件层面静态调度策略的蜻蜓网络拓扑。
- 对模型与数据的分割,包括以何种策略分割、分割批次的大小;对此,论文提出了基于GPU执行的SIMT特性的任务打包和拆分方法,以及相对应的自适应线程映射技术。
- 分布式系统设计,包括向外扩展性的实现、节点校正、节点之间的同步机制、节点之间如何联系传输;对此,论文提出了ISA架构的HAC指令与DESKEW指令等,模拟达到同步机制的效果,在容错率上,采用前向纠错来进行校正,在传输上,采用C2C结构作为节点之间的传输纽带,并采用软件层面的流控制来划定传输模式。
此外,通过保证确定性执行,可以提高计算性能与稳定性,确定性执行能保证计算始终在限定时间内产生一致的输出。通过对单次迭代计算本身的优化,也可提高计算性能,对计算形式及其特性进行分类,又可分为计算密集型与内存密集型的计算,从而产生面向运算符的多重运算器缝合方案。
在讨论计算性能时,时间与空间成本的对立与相互转换是一个永恒的命题,体系结构在机器学习领域的应用,则是试图在软硬件之间建立联系,从更底层的网络结构、编译器结构出发,从而在时间与空间成本中取得平衡,来使性能与收益最大化。
参考文献:
[1] J. Kim, W. J. Dally, S. Scott and D. Abts, “Technology-Driven, Highly-Scalable Dragonfly Topology,” 2008 International Symposium on Computer Architecture, Beijing, China, 2008, pp. 77-88, doi: 10.1109/ISCA.2008.19.
[2] C2C接口——推动移动产业未来发展与创新.Brian Carlson http://www.chinaaet.com/article/150357
[3] Dennis Abts, Garrin Kimmell, Andrew C. Ling, John Kim, Matthew Boyd, Andrew Bitar, Sahil Parmar, Ibrahim Ahmed, Roberto DiCecco, David Han, et al.: A software-defined tensor streaming multiprocessor for large-scale machine learning. ISCA 2022: 567-580.
[4] Zhen Zheng, Xuanda Yang, Pengzhan Zhao, Guoping Long, Kai Zhu, Feiwen Zhu, Wenyi Zhao, Xiaoyong Liu, Jun Yang, Jidong Zhai, Shuaiwen Leon Song, Wei Lin: AStitch: enabling a new multidimensional optimization space for memory-intensive ML training and inference on modern SIMT architectures. ASPLOS 2022: 359- 373.