
BART Architecture
源码中各class的介绍与模型结构:
- BartLearnedPositionalEmbedding 该class定义了BART模型中的位置嵌入层。与传统的位置嵌入不同,BART采用了可学习的位置嵌入,以提高模型的泛化能力。该层的输入是token嵌入和位置编码,输出是嵌入向量。
- BartAttention 该class定义了BART模型中的自注意力机制。该层的输入是query、key和value,输出是加权的value向量。BART采用了多头注意力机制,可以捕捉不同的特征。
- BartEncoderLayer/BartDecoderLayer 该class定义了BART模型中的编码器层和解码器层。这两个层的结构类似,都包含了多头注意力、前向传播和残差连接等模块。编码器层用于对输入文本进行编码,解码器层用于生成目标文本。
BartEncoder/BartDecoder 该class定义了BART模型中的编码器和解码器。编码器由多个编码器层组成,用于对输入文本进行编码。解码器由多个解码器层组成,用于生成目标文本。编码器和解码器之间还包含了一个连接层,用于将编码器的输出传递给解码器。
- BartModel 该class定义了完整的BART模型,包括编码器、解码器和连接层等。该模型可以用于生成式任务,如文本摘要、机器翻译等。
- BartForConditionalGeneration 该class继承自BartModel,用于有条件的生成任务,如文本摘要、机器翻译等。该模型包含了一个线性层,用于将解码器的输出映射为目标文本。
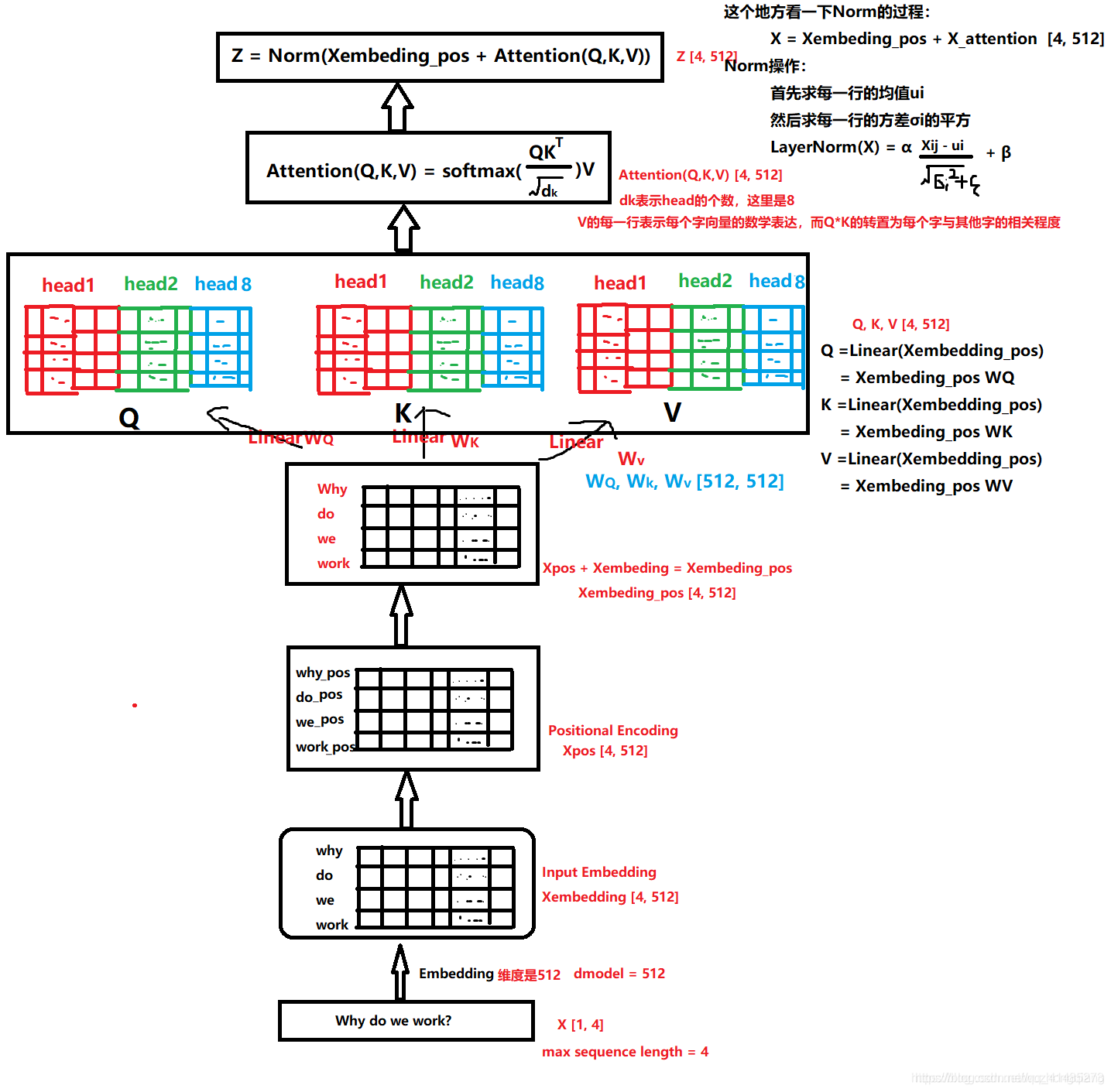
BartAttention
Multi-headed attention from ‘Attention Is All You Need’ paper
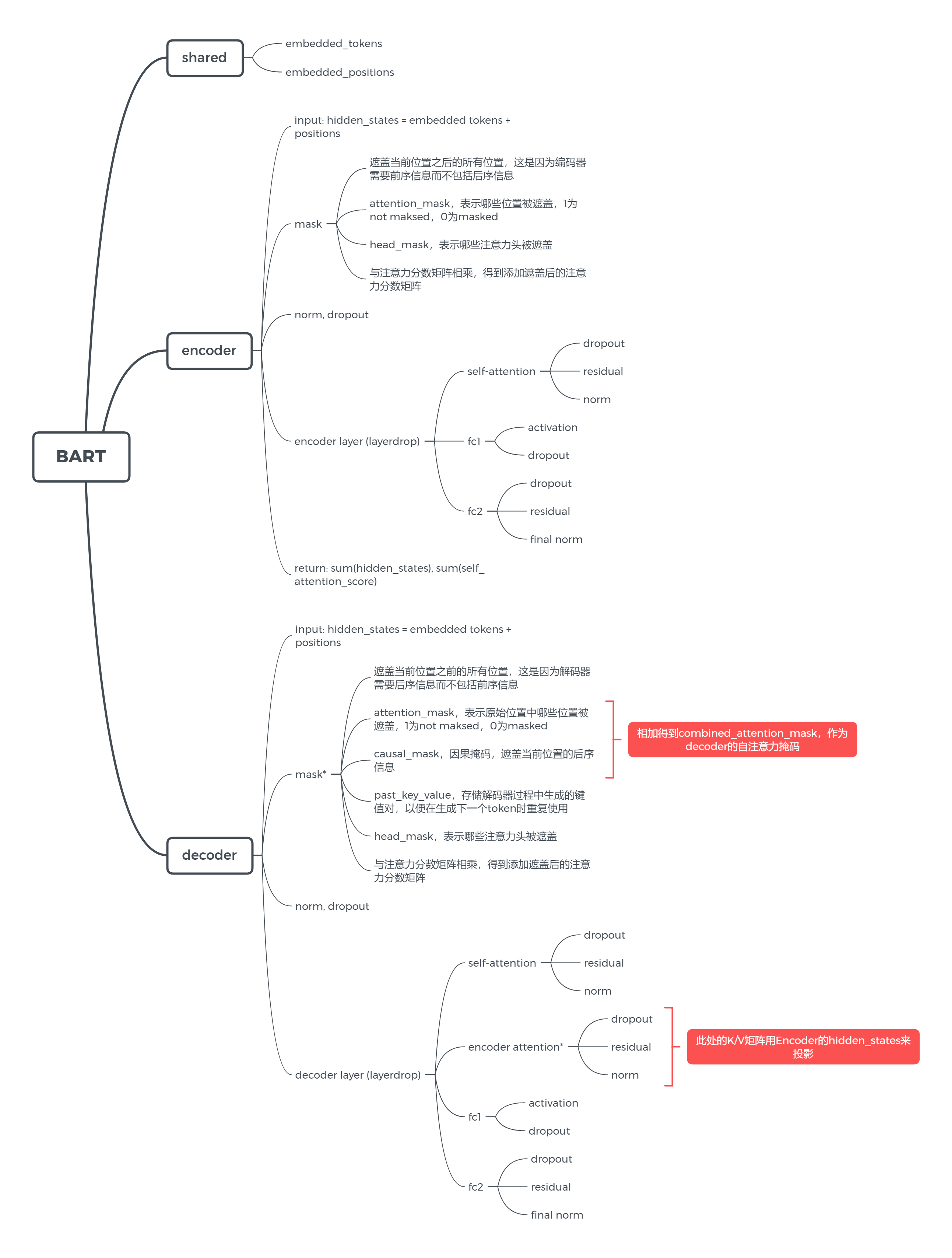
BartModel
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
def __init__(self, config: BartConfig):
super().__init__(config)
"""
padding_idx表示在词汇表中的填充符号的索引,一般为0。
在BART模型中,输入文本会被分成一系列的token,如果某个样本的token数量不足时,
就需要在其后添加填充符号,以保证所有样本的token数量一致。
vocab_size表示词汇表的大小,即词汇表中不同单词的数量。
它们都是模型的输入参数。
"""
padding_idx, vocab_size = config.pad_token_id, config.vocab_size
# config.d_model:超参数,它指定了模型中隐藏层的大小,也称为嵌入维度
# nn.Embedding类将输入序列中的每个单词映射到一个嵌入向量
# 这个映射是通过将单词的整数索引作为输入,查找embed_tokens.weight(嵌入向量W)矩阵,返回相应的嵌入向量来实现的
# embed_tokens.weight shape like (vocab_size, config.d_model)
self.shared = nn.Embedding(vocab_size, config.d_model, padding_idx)
self.encoder = BartEncoder(config, self.shared)
self.decoder = BartDecoder(config, self.shared)
# Initialize weights and apply final processing
self.post_init()
参数
输入参数
- padding_idx:表示在词汇表中的填充符号的索引,一般为0。在BART模型中,输入文本会被分成一系列的token,如果某个样本的token数量不足时,就需要在其后添加填充符号,以保证所有样本的token数量一致。
- vocab_size:表示词汇表的大小,即词汇表中不同单词的数量。
超参数
- config.d_model:超参数,它指定了模型中隐藏层的大小,也称为嵌入维度。
embed_tokens.weight shape like (vocab_size, config.d_model)
forward
输入序列首先被转化为单词索引序列,然后通过self.shared层进行嵌入映射,通过将单词的整数索引作为输入,查找embed_tokens.weight(嵌入向量W)矩阵,返回相应的嵌入向量。这些嵌入向量embedded_tokens将作为模型的输入,依次被传递到编码器和解码器中进行处理,生成对应的输出。
1
2
3
4
5
6
7
8
9
10
return Seq2SeqModelOutput(
last_hidden_state=decoder_outputs.last_hidden_state,
past_key_values=decoder_outputs.past_key_values,
decoder_hidden_states=decoder_outputs.hidden_states,
decoder_attentions=decoder_outputs.attentions,
cross_attentions=decoder_outputs.cross_attentions,
encoder_last_hidden_state=encoder_outputs.last_hidden_state,
encoder_hidden_states=encoder_outputs.hidden_states,
encoder_attentions=encoder_outputs.attentions,
)
shared
在BART模型中,有些层需要在编码器和解码器之间共享,例如嵌入层(也就是上面提到的embedded_tokens,存有嵌入向量权重矩阵)。因此,BART模型使用了一个称为”shared”的参数,来将这些层在编码器和解码器之间共享。这个shared参数是一个可学习的参数,可以在模型的训练过程中进行更新。这样,BART模型就可以在编码器和解码器之间共享这些层,从而减少了模型中的参数数量,加快了模型的训练速度,并提高了模型的泛化能力。
在实现过程中,BARTModel类中的shared属性是一个nn.Embedding类,nn.Embedding类将一个整数张量中的每个整数索引映射到一个固定大小的嵌入向量,它通过查找嵌入矩阵中相应的行来实现这个映射。
在模型的前向传播过程中,输入序列的每个单词索引都通过self.shared进行映射,得到一个固定大小的嵌入向量,作为模型的输入。
BartEncoder
Self-attention mask
在Encoder中,自注意力掩码被设置为遮盖当前位置之后的所有位置,这是因为编码器需要前序信息而不包括后序信息。自注意力掩码信息被储存在attention_mask张量中,大小为(batch_size, sequence_length),用于遮盖输入序列中的一些位置以表示哪些位置可以被模型忽略,1为not maksed,0为masked。
head_mask:指定需要遮盖的注意力头,减少计算量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# expand attention_mask
if attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
attention_mask = _expand_mask(attention_mask, inputs_embeds.dtype) # 与自注意力得分矩阵的大小匹配
encoder_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
# check if head_mask has a correct number of layers specified if desired
if head_mask is not None:
if head_mask.size()[0] != (len(self.layers)):
raise ValueError(
f"The head_mask should be specified for {len(self.layers)} layers, but it is for"
f" {head_mask.size()[0]}."
)
注意力分数矩阵是一个形状为 [batch_size, num_heads, sequence_length, sequence_length] 的 4D 张量,其中 batch_size 是批次大小,num_heads 是注意力头的数量,sequence_length 是序列的长度。注意力分数矩阵中的每个元素都代表了一个位置对于另一个位置的注意力权重。
超参数
- dropout:对于每个Transformer模块的输入向量,以config.dropout的概率将其中一部分设置为0,以达到正则化的效果。
- layerdrop:对于每个Transformer模块,以config.encoder_layerdrop的概率不更新其中一部分模块,以达到正则化的效果。
学习嵌入信息
- embed_tokens(
nn.Embedding):学习的嵌入向量矩阵 - embed_positions(
BartLearnedPositionalEmbedding):学习的位置嵌入矩阵
BartLearnedPositionalEmbedding
BartLearnedPositionalEmbedding类继承了nn.Embedding类,用于学习位置嵌入(positional embeddings)。该类的输入参数是num_embeddings和embedding_dim,分别指定了可能的位置数量和嵌入的维度。
BartLearnedPositionalEmbedding类的构造函数使用了一个特殊的hack,即如果padding_idx被指定了,则需要通过偏移(offset)将嵌入id加2,同时调整num_embeddings,以便在padding_idx位置插入特殊嵌入。
例子:
假设我们有一个BART模型,它有6个位置嵌入和2个特殊的嵌入(BOS和EOS)。在这种情况下,如果我们将padding_idx设置为1,则所有嵌入id都需要偏移2个位置,以便将填充嵌入插入到1的位置。因此,新的嵌入id将是:
- 0:BOS(begin-of-sequence)嵌入
- 1:填充嵌入(padding_idx)
- 2:EOS(end-of-sequence)嵌入
- 3:第一个位置嵌入
- 4:第二个位置嵌入
- 5:第三个位置嵌入
在BartLearnedPositionalEmbedding类的forward方法中,输入张量的形状被期望是[bsz x seqlen]。该方法首先计算出输入序列中每个令牌的位置,然后将这些位置传递给nn.Embedding的forward方法。为了计算令牌的位置,使用了torch.arange()函数生成从past_key_values_length到past_key_values_length+seq_len的序列,这些序列在第一维上被扩展为bsz,以匹配输入张量的形状,即[bsz, seq_len]。
最后,将位置id与偏移值相加,以获得在BART模型中使用的实际嵌入id。在实现中,使用了PyTorch的super()方法调用父类nn.Embedding的forward方法,以获取位置序列的嵌入向量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class BartLearnedPositionalEmbedding(nn.Embedding):
"""
This module learns positional embeddings up to a fixed maximum size.
"""
def __init__(self, num_embeddings: int, embedding_dim: int):
# Bart is set up so that if padding_idx is specified then offset the embedding ids by 2
# and adjust num_embeddings appropriately. Other models don't have this hack
self.offset = 2
super().__init__(num_embeddings + self.offset, embedding_dim)
def forward(self, input_ids: torch.Tensor, past_key_values_length: int = 0):
"""`input_ids' shape is expected to be [bsz x seqlen]."""
bsz, seq_len = input_ids.shape[:2]
positions = torch.arange(
past_key_values_length, past_key_values_length + seq_len, dtype=torch.long, device=self.weight.device
).expand(bsz, -1)
return super().forward(positions + self.offset)
BartEncoderLayer
| BartEncoderLayer |
|---|
| self-attention |
| dropout, +=residual(随机失活,残差连接) |
| self-attention layer norm |
| fc1, activation |
| dropout, fc2 |
| dropout, +=residual |
| final norm |
Architecture
| BartEncoder |
|---|
| 将词嵌入向量与位置嵌入向量相加,得到hidden_states |
| norm, dropout |
| BartEncoderLayer for config.encoder_layers(会以layerdrop的概率决定是否跳过layer), 每一层的状态、自注意力矩阵会被分别累加并返回 |
BartDecoder
与Encoder的区别在于自注意力掩码与交叉注意层。
Self-attention mask
在Decoder中,自注意力掩码需要遮盖当前位置之后的所有位置,以及遮盖所有编码器的输出位置,以防止解码器在生成输出时访问来自未来的信息和编码器输出中不应访问的信息。
_prepare_decoder_attention_mask()会生成一个causal_mask,即遮盖当前位置的后序信息,再加上原先的attention_mask(忽略pad token),得到combined_attention_mask作为decoder的自注意力掩码,用于计算decoder的自注意力得分。
past_key_value是在decoder中使用的一种机制(自注意力蒸馏),用于存储解码器过程中生成的键值对,以便在生成下一个token时重复使用,减少计算量。
BartDecoderLayer
此处的交叉注意力层,是指利用Encoder的hidden_states来投影得到Key/Value矩阵,利用Decoder的hidden_states来投影得到Query矩阵。引入encoder的信息来计算交叉注意力得分。
| BartDecoderLayer |
|---|
| self-attention |
| dropout, +=residual(随机失活,残差连接) |
| self-attention layer norm |
| encoder_attn(交叉注意力) |
| dropout, +=residual |
| encoder_attn_layer_norm |
| fc1, activation |
| dropout, fc2 |
| dropout, +=residual |
| final norm |
Architecture
| BartDecoder |
|---|
| 将词嵌入向量与位置嵌入向量相加,得到hidden_states |
| norm, dropout |
| BartDecoderLayer for config.decoder_layers(会以layerdrop的概率决定是否跳过layer), 每一层的状态、自注意力矩阵、交叉注意力矩阵会被分别累加并返回,还会返回上一状态与上一解码键值对的信息,避免冗余计算 |
下一步工作
接下来要继续读的:
- bartAttention的实现精读
- 预训练model的方式
- 用于不同下游任务的微调
- conditional generation,生成文本摘要,在模型最后具有一个language modeling head,是一个线性层
- sequence classification,序列分类,在模型最后具有一个分类头(classification head)
- question answering,问答,在模型最后有一个具有一个线性层
- 用于causal language model的bart decoder